Index more domain data into elasticsearch #5979
Conversation
|
@ericholscher I found some domains which don't have proper html strucutre. So there's no proper domain signature and no proper domain doc strings. |
I will add the tests, once we are sure of the working. |
* remove and from docsearch API and start using . * remove unnecessary fields from the PageDocument to index only relevant data into elasticsearch. * Add to search fields in faceted_Search.py. * Don't get from parse_json -- it is not required. * Update to show domains docstrings in results in page.
|
@ericholscher |
|
Those aren't in Sphinx Domain's: https://raw.githubusercontent.com/celery/celery/241d2e8ca85a87a2a6d01380d56eb230310868e3/docs/userguide/configuration.rst |
|
@ericholscher
I believe, this sphinx domain is coming from this -- |
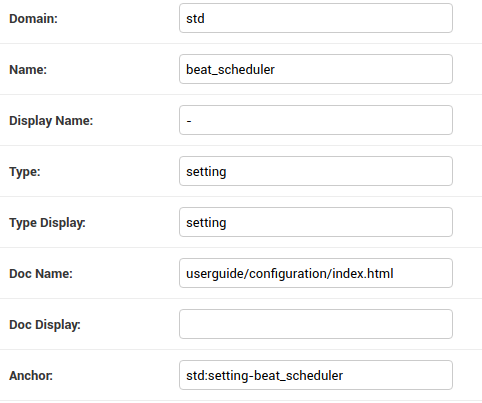


| 'anchor': fields.KeywordField(), | ||
|
|
||
| # For showing in the search result | ||
| 'type_display': fields.TextField(), | ||
| 'doc_display': fields.TextField(), |
There was a problem hiding this comment.
We don't need doc_display -- because the main title of each result contains the doc_display.
But I have undoed the change for type_display -- we can make use of this.
There was a problem hiding this comment.
😕
I can't seem to find a good way to display every information.
type_display looks unncessary when we are displaying role_name.
There was a problem hiding this comment.
Well, sure. They are showing the same information. I believe the type_display is meant for human readable output, and role_name is not, no?
There was a problem hiding this comment.
Both are quite readable:
py:function
std:confval
py:class
There was a problem hiding this comment.
I think configuration value over confval is much better for non-technical users. We should definitely try to use the display value, that's the whole reason it exists if for this use.
There was a problem hiding this comment.
@ericholscher
I realised (while testing) that some sphinx domains don't have values for type_display.
Should we still show for those who have? or just keep showing role_name?
|
|
||
| {% if inner_hit.source.display_name|length >= 1 %} | ||
| ({{ inner_hit.source.role_name }}) {{ inner_hit.source.display_name}} | ||
| {% with "100" as MAX_SUBSTRING_LIMIT %} |
There was a problem hiding this comment.
I'm feeling the pain of maintaining multiple sets of result HTML. We should consider trying to get the site search using the search as you type code, hopefully with minimal changes from the theme code. That way we don't have 3 places to change HTML.
The goal will be to ship search as you type across all of RTD so we only have to maintain one set of results, but baby steps :)
There was a problem hiding this comment.
Yes... maintaining multiple sets of html is definitely a pain.
The goal will be to ship search as you type across all of RTD so we only have to maintain one set of results, but baby steps :)
I think that's quite a big refactor and we can target that after this PR?
|
This looks like a great approach. Let's see if we can get it deployed this week after we fix up tests. 👍 |
WIP
Related PR in readthedocs-sphinx-search -- readthedocs/readthedocs-sphinx-search#42