DOC: Set value for undefined variables in examples #51389
There are no files selected for viewing
| Original file line number | Diff line number | Diff line change |
|---|---|---|
|
|
@@ -2204,7 +2204,7 @@ def to_excel( | |
|
|
||
| >>> with pd.ExcelWriter('output.xlsx', | ||
| ... mode='a') as writer: # doctest: +SKIP | ||
| ... df1.to_excel(writer, sheet_name='Sheet_name_3') | ||
|
|
||
| To set the library that is used to write the Excel file, | ||
| you can pass the `engine` keyword (the default engine is | ||
|
|
@@ -5864,9 +5864,9 @@ def pipe( | |
| Alternatively a ``(callable, data_keyword)`` tuple where | ||
| ``data_keyword`` is a string indicating the keyword of | ||
| ``callable`` that expects the {klass}. | ||
| *args : iterable, optional | ||
| Positional arguments passed into ``func``. | ||
| **kwargs : mapping, optional | ||
| A dictionary of keyword arguments passed into ``func``. | ||
|
|
||
| Returns | ||
|
|
@@ -5883,25 +5883,67 @@ def pipe( | |
| Notes | ||
| ----- | ||
| Use ``.pipe`` when chaining together functions that expect | ||
| Series, DataFrames or GroupBy objects. | ||
|
|
||
| Examples | ||
| -------- | ||
| Constructing a income DataFrame from a dictionary. | ||
|
|
||
| >>> data = [[8000, 1000], [9500, np.nan], [5000, 2000]] | ||
| >>> df = pd.DataFrame(data, columns=['Salary', 'Others']) | ||
| >>> df | ||
| Salary Others | ||
| 0 8000 1000.0 | ||
| 1 9500 NaN | ||
| 2 5000 2000.0 | ||
|
|
||
| Functions that perform tax reductions on an income DataFrame. | ||
|
|
||
| >>> def subtract_federal_tax(df): | ||
| ... return df * 0.9 | ||
| >>> def subtract_state_tax(df, rate): | ||
| ... return df * (1 - rate) | ||
| >>> def subtract_national_insurance(df, rate, rate_increase): | ||
| ... new_rate = rate + rate_increase | ||
| ... return df * (1 - new_rate) | ||
|
|
||
| Instead of writing | ||
|
|
||
| >>> subtract_national_insurance( | ||
| ... subtract_state_tax(subtract_federal_tax(df),rate=0.12), | ||
| ... rate=0.05, | ||
| ... rate_increase=0.02) # doctest: +SKIP | ||
|
|
||
| You can write | ||
|
|
||
| >>> df.pipe( | ||
| ... subtract_federal_tax | ||
| ... ).pipe( | ||
| ... subtract_state_tax, rate=0.12 | ||
| ... ).pipe(subtract_national_insurance, rate=0.05, rate_increase=0.02) | ||
|
There was a problem hiding this comment.
Does this comment refer to the parenthesis wrapping this whole block? If that's the case, I don't think this is true. The original syntax is much more common and readable than this in my opinion. This is what we've been doing in the docs that I know, it's how code was chained in the original post about method chaining, it's also the syntax that Matt Harrison uses in the Effective pandas book, and it's what I would write. To be clear, I'm referring to using (df.pipe(foo)
.pipe(bar)
.pipe(foobar)
)instead of df.pipe(
foo
).pipe(
bar
).pipe(
foobar
)I'm fine with whatever (even if I personally found the former much more readable), but I wouldn't ask people to change the the latter because the former is not what someone would write, because I think many people would actually write that. :) |
||
| Salary Others | ||
| 0 5892.48 736.56 | ||
| 1 6997.32 NaN | ||
| 2 3682.80 1473.12 | ||
|
|
||
| If you have a function that takes the data as (say) the second | ||
| argument, pass a tuple indicating which keyword expects the | ||
| data. For example, suppose ``national_insurance`` takes its data as ``df`` | ||
| in the second argument: | ||
|
|
||
| >>> def subtract_national_insurance(rate, df, rate_increase): | ||
| ... new_rate = rate + rate_increase | ||
| ... return df * (1 - new_rate) | ||
| >>> df.pipe( | ||
| ... subtract_federal_tax | ||
| ... ).pipe( | ||
| ... subtract_state_tax, rate=0.12 | ||
| ... ).pipe((subtract_national_insurance, 'df'), | ||
| ... rate=0.05, rate_increase=0.02) | ||
| Salary Others | ||
| 0 5892.48 736.56 | ||
| 1 6997.32 NaN | ||
| 2 3682.80 1473.12 | ||
| """ | ||
| if using_copy_on_write(): | ||
| return common.pipe(self.copy(deep=None), func, *args, **kwargs) | ||
|
|
||
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
this one is throwing an error in CI:
I think you need to remove
# doctest: +SKIPfrom a few lines aboveThere was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Fixed the error!
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Thanks @kkangs0226! ... Is there any chance that you could run this command? :
./scripts/validate_docstrings.py pandas.core.apply.relabel_result
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Here is the output, it still flags as failed example but I think @MarcoGorelli has mentioned that this error is unrelated. It seems to be one of F821 undefined errors.
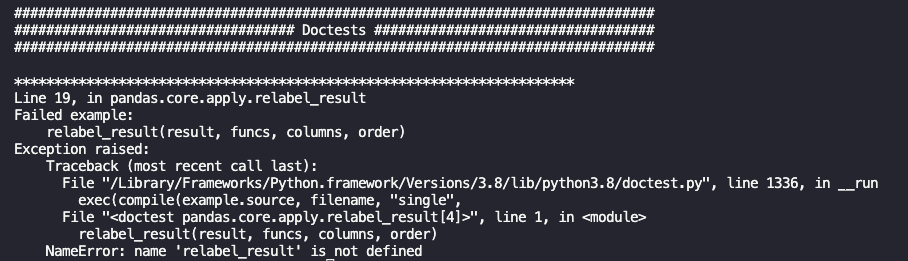
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
sorry I meant that the
Ubuntu / Numpy Dev (pull_request)CI job's failure is unrelatedthis one looks related, you may need to put something like
from pandas.core.apply import relabel_resultat the top of the doctestThere was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
thanks for trying - sure, I'll take a look tomorrow, hopefully there's a simple fix
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
The docstring of
relabel_resulthas many errors. I see 16:The summary should be in one line, the parameters and even the subtitles are incorrect. (They shouldn't have ":", it should be
Examples, notExamples:) etc.But at the beginning of the function it's written "Internal function...", and this is not on the documentation website.
Should we test internal functions docstrings?! @MarcoGorelli
Thank you @kkangs0226... We'll get there. :-)
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
I don't think we should fix the whole docstring here. Let's merge this when all the problems to the original PR scope are fixed, and open follow up PRs for anything else we want to fix.
@kkangs0226 can you provide the whole traceback for the error please? With only the error and the line you shared I don't know what the problem can be, and more context would be helpful.
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Here is the entire traceback, hope it is able to provide more context.
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
ok, got it - I'll post a new review comment showing how I'd go about fixing this (as it's a bit long and easy to get lost in a thread)