Benchmark epi_archive operations with and without compactification
#111
Comments
|
@brookslogan Are we concerned about user or system speed with performance?
Seeing that we use I know I should be testing |
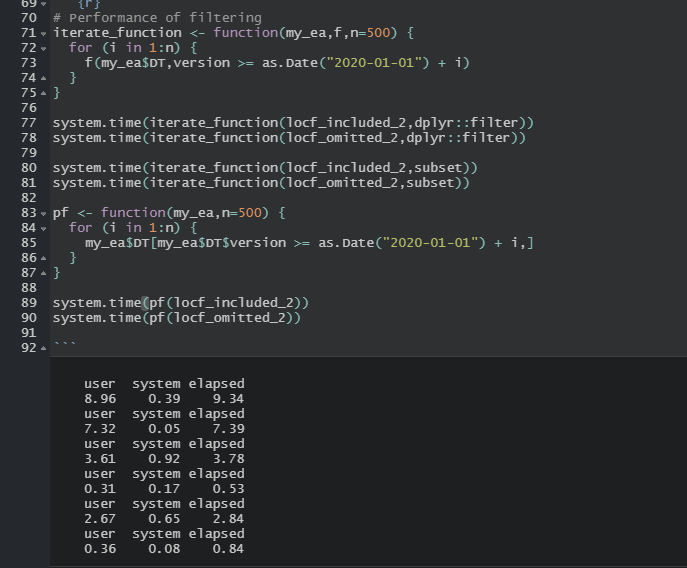
|
Finished with PR #118. |
|
Do we use I think it's natural to assume that Benchmarking has a lot of gotchas; we should probably use a pre-packaged solution like |
|
@brookslogan No, I am not using If we are only testing |
|
Right, I meant
Regarding system vs. user vs. real: I think we care separately about system+user and real: based on our use case:
|
How would I go about calculating "real" time? I know what I did with elapsed time is Case 2, as elapsed time is the sum of system and user time. |
|
I think we discussed this via Slack; are there any remaining questions here? Did you find from reading about the different benchmarking methods that the one used in the vignette now is considered accurate/reliable or not? |
|
Closing as completed by #101. |
Compactification (#101) should save space (at least once/if the original input data is garbage collected), but does it save (meaningful) time? We should benchmark some
epi_archiveoperations (construction,as_of,epix_slideoverhead, ...) with and without compactification, and compare against other operations (download time, costs of commonffunctions passed toepi_slide, etc.) to contextualize whether any changes are important. If benchmarking shows this actually slows down the epi archive considerably, then we should reconsider the default for compactifaction; if benchmarking shows a significant speedup, then we might want to show this off in a vignette (and perhaps try to work on move to an encapsulated design or dtplyr approach so we can perhaps message or be silent when compactifying by default rather than warning).The text was updated successfully, but these errors were encountered: