PERF: Improve SeriesGroupBy.value_counts performances with categorical values. #46940
Conversation
43d8e34 to
6aa38db
Compare
|
do we have asv's for this? can you show. (if not, or they are not representative of the OP can you add) |
It seems there is no asv for this. I will add one once I succeed to run the benchmark suite. |
|
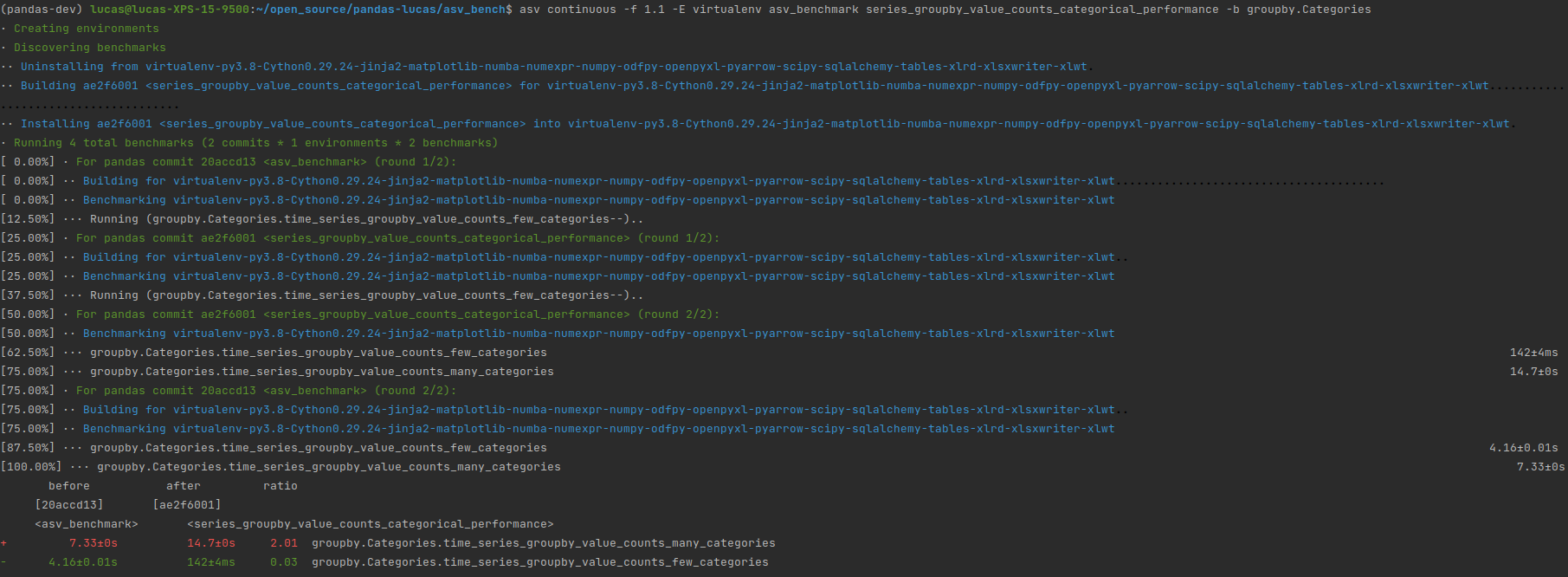
After benchmarking, I noticed that the current
It shows a x30 performance boost for a small number of categories, and a x2 slow down with many categories. I feel this fix is still interesting considering the slow down for many categories is negligible regarding the boost introduced for a small number of categories. I guess it depends on how many categories people use in general. @jreback do you have an opinion on it ? Also, I profiled the
|

| if is_categorical_dtype(val.dtype) or ( | ||
| bins is not None and not np.iterable(bins) | ||
| ): | ||
| if is_categorical_dtype(val.dtype): |
There was a problem hiding this comment.
can we just call the appropriate implementation. creating a new grouper and calling like this just obfuscatest he code. would really prefer simply to have a single implementation and just call it.
There was a problem hiding this comment.
I understand why it obfuscates the code, and I wonder what would be the approriate implementation here. Do you mean introducing a method _groupby_value_counts containing most of the current DataFrame implementation logic, that would be called by both Series and DataFrame implementation ?
There was a problem hiding this comment.
@jreback could you please elaborate what you think would be the approriate implementation to call here ?
There was a problem hiding this comment.
need to refactor the value counts to a separate function then just call it for frame and series
There was a problem hiding this comment.
After investigation, I think the common implementation should rely on a groupby.size (ie similar to the current DataFrame implementation) instead of the logic of the current Series implementation which looks more cumbersome. However, the DataFrame implementation relying on groupby.size holds a bug when grouping on a grouper with a freq, cf #47286. Therefore, having such a common implementation to Series/DataFrame would break test_series_groupby_value_counts_with_grouper.
|
This pull request is stale because it has been open for thirty days with no activity. Please update and respond to this comment if you're still interested in working on this. |
|
I am no longer working on this pull request, I unassigned me of #46202. |
|
Thanks for your efforts so far @LucasG0. I'm going to close this PR as it has gone stale, but can reopen if anyone wants to tackle in the future |
doc/source/whatsnew/vX.X.X.rstfile if fixing a bug or adding a new feature.The performance issue comes from the fact the categorical path relies on
GroupBy.apply. Actually,SeriesGroupby.value_countsandDataFrameGroupBy.value_countshave different implementations, and I feel they should both rely on a single one. Typically, the Series implementation looks more complicated than the DataFrame one (which relies onGroupBy.size), this is why this change creates aDataFrameGroupByobject to rely on the DataFrame implementation. Ideally, I think the entire Series implementation could rely on the DataFrame one (not only the categorical path). Also, I have a small doubt whether creating a newDataFrameGroupByobject out of aSeriesGroupByone is a good practice or not, so if there is a better way to do here feel free to suggest it.Note I did not add a test in this PR as it fixes performance only, but I manually tested and confirmed the performance improvement.