BUG: df.pivot_table fails when margin is True and only columns is defined #31088
Conversation
pandas/tests/reshape/test_pivot.py
Outdated
| ), | ||
| ), | ||
| ( | ||
| ["A", "B", "C"], |
There was a problem hiding this comment.
Does this test anything different from the test preceding it? It not I think can be removed
There was a problem hiding this comment.
thanks for your quick response! @WillAyd
emm, this shows different number of levels for columns, is this a bit redendunt? if so, i will remove
There was a problem hiding this comment.
I think can be removed; the one preceding already tests for a multi index
| table_pieces.append(Series(margin[key], index=[all_key])) | ||
| # GH31016 this is to calculate margin for each group, and assign | ||
| # corresponded key as index | ||
| transformed_piece = DataFrame(piece.apply(aggfunc)).T |
There was a problem hiding this comment.
Does this have any performance impacts?
There was a problem hiding this comment.
might be? i was thinking of it as well
how to measure it? do you mean create a giant mock dataset and time it? any suggestions? would like to test it out!
There was a problem hiding this comment.
We have asvs in benchmarks/reshape.py that would be good to run here at least
There was a problem hiding this comment.
thanks! @WillAyd i am not very familiar with asv bench, but i see some tests starting with time_pivot****, shall I add a new test in there?
There was a problem hiding this comment.
Run the existing ones first:
cd asv_bench
asv continuous upstream/master HEAD -b reshape.PivotTableThere was a problem hiding this comment.

just copied and pasted and tested a bit
There was a problem hiding this comment.
Run the existing ones first:
cd asv_bench asv continuous upstream/master HEAD -b reshape.PivotTable
oops! thanks for the tip!! did not see it 😅 will run
There was a problem hiding this comment.
running asv on current i get: BENCHMARKS NOT SIGNIFICANTLY CHANGED.
but i do find an issue with self-review, will investigate and fix tomorrow. thanks for the help on asv @WillAyd
|
Hi, @WillAyd , i think the PR is ok to review now. Please let me know how you plan to do the asv bechmark for this piece, shall I add a test in asv_bench for this one? (as mentioned above, running asv on the current locally is good) |
|
looks good, can you rebase. adding an asv would be nice as well. |
|
Hello @charlesdong1991! Thanks for updating this PR. We checked the lines you've touched for PEP 8 issues, and found: There are currently no PEP 8 issues detected in this Pull Request. Cheers! 🍻 Comment last updated at 2020-01-18 18:21:01 UTC |
|
emm, running asv locally with new tests added, this manipulation does perform much slower than other tests, and the second trial even failed. Any idea/How to interpret why the second one failed? is it because it is too slow and then is above the threshold? @jreback @WillAyd I am pretty new to asv, and some feedbacks would be highly appreciated! Thanks!
|
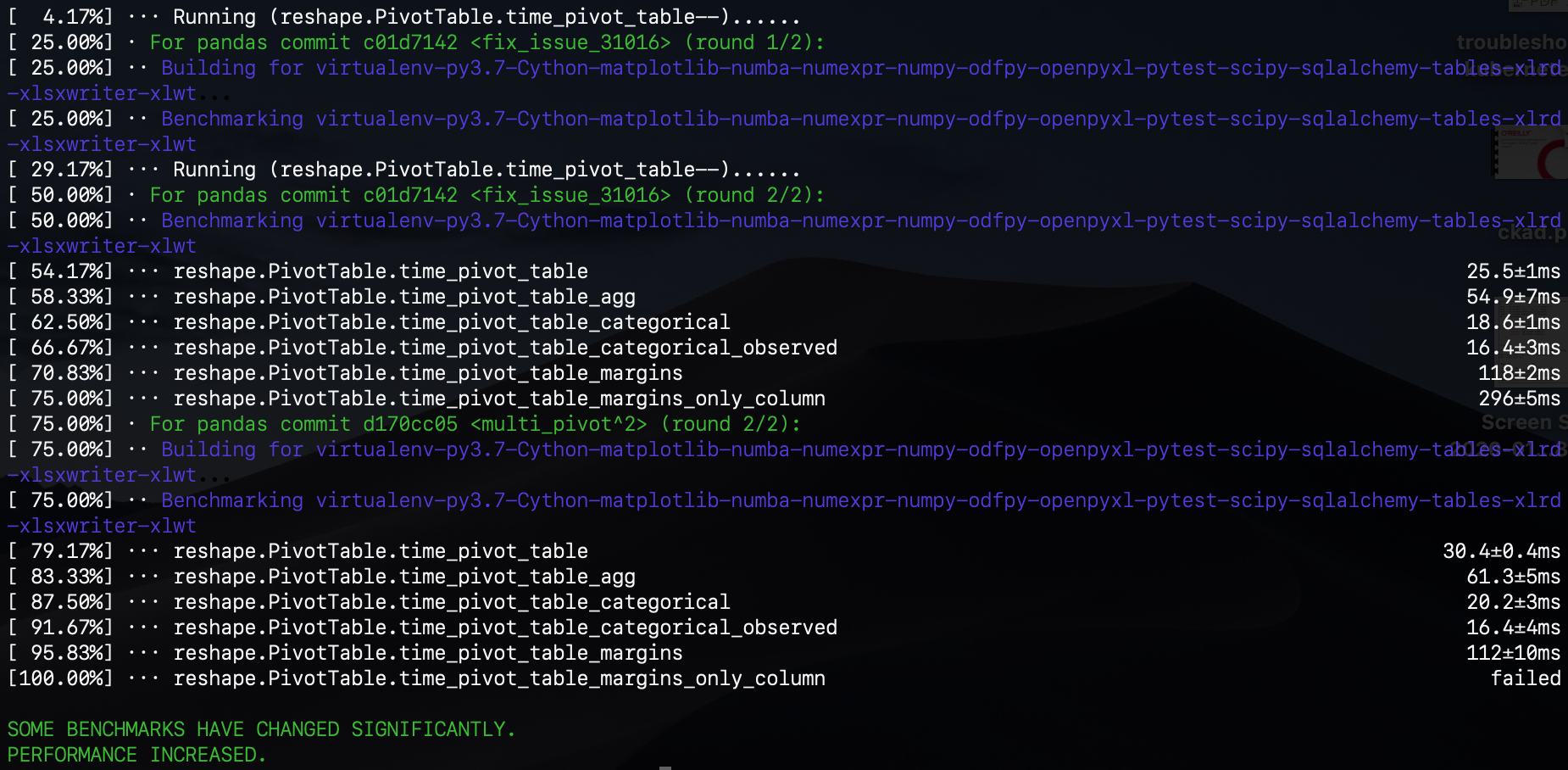
|
@charlesdong1991 if you can post the actual shell output instead of a screenshot typically better. That said it doesn’t look like things changed that much. Not sure why the second run failed but you can retry with —show-stderr option |
sorry, is this what you mean by posting actual output? @WillAyd Yeah, thanks mate! And seems the first round is running the code in my current PR, and second one is using the code on master branch. so i think we are good! @WillAyd @jreback not sure why the performance even gets slightly better 😅 but at least it's not getting worse, haha |
|
lgtm. @WillAyd |
|
Thanks @charlesdong1991 |
| # GH31016 this is to calculate margin for each group, and assign | ||
| # corresponded key as index | ||
| transformed_piece = DataFrame(piece.apply(aggfunc)).T | ||
| transformed_piece.index = Index([all_key], name=piece.index.name) |
There was a problem hiding this comment.
@charlesdong1991 what if piece.index is a MultiIndex? .name here will be None. Do we need to use .names somewhere?
There was a problem hiding this comment.
you are right, it will be None if it is a MultiIndex. Need to have a deeper look to see it is reasonable to use .names because if using it, then that's a frozen list iirc, and we could not assign to index.name. Also if a MI here, then maybe also need to use MultiIndex instead of Index.
black pandasgit diff upstream/master -u -- "*.py" | flake8 --diff