BUG: pd.read_sql_table() raises unknown column error when column name of a table contains %
#37157
Closed
3 tasks done
Comments
|
Using raw sqlalchemy to fetch the results does not raise. import pandas as pd
from sqlalchemy import create_engine
print(pd.__version__)
connection_string = "mysql+mysqldb://root:pw@localhost:3306/test"
con = create_engine(connection_string).connect()
with con:
result = con.execute("select * from my_table;")
values = [dict(row) for row in result]
df = pd.DataFrame(values)
print(df)
con.close()Output: Same for connection_string = "mysql+mysqldb://root:pw[@localhost:3306/test"
con = create_engine(connection_string).connect()
with con:
result = con.execute("select * from my_table;")
df = pd.DataFrame(result.fetchall())
print(df)
con.close()Output |
|
take |
|
git bisect gave: |
5 tasks
|
this was deliberately changed in #34212 so not sure why you think this is a regression. |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
I have checked that this issue has not already been reported.
I have confirmed this bug exists on the latest version of pandas.
(optional) I have confirmed this bug exists on the master branch of pandas.
Note: Please read this guide detailing how to provide the necessary information for us to reproduce your bug.
Code Sample, a copy-pastable example
Mysql Create Table
Problem description
[this should explain why the current behaviour is a problem and why the expected output is a better solution]
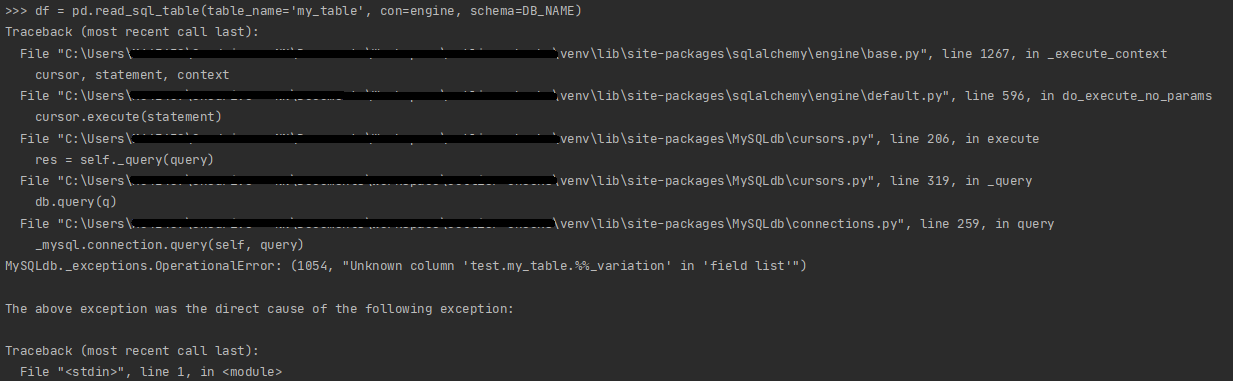
As you can see above, the
%_variationcolumn is read as%%_variationin the SELECT statement.But the
%%_variationcolumn is not present in the database and thus reading this table from the database provides an error.Expected Output
I expect pandas to read the table from the database.
I tried reading with pandas version 1.0.5 and I was able to read the table from the database without any problem.

Output of
pd.show_versions()INSTALLED VERSIONS
commit : db08276
python : 3.7.7.final.0
python-bits : 64
OS : Windows
OS-release : 10
Version : 10.0.18362
machine : AMD64
processor : Intel64 Family 6 Model 78 Stepping 3, GenuineIntel
byteorder : little
LC_ALL : None
LANG : None
LOCALE : None.None
pandas : 1.1.3
numpy : 1.19.0
pytz : 2020.1
dateutil : 2.8.1
pip : 20.2.3
setuptools : 50.3.0
Cython : None
pytest : None
hypothesis : None
sphinx : None
blosc : None
feather : None
xlsxwriter : 1.2.9
lxml.etree : None
html5lib : None
pymysql : None
psycopg2 : None
jinja2 : None
IPython : None
pandas_datareader: None
bs4 : None
bottleneck : None
fsspec : None
fastparquet : None
gcsfs : None
matplotlib : None
numexpr : None
odfpy : None
openpyxl : None
pandas_gbq : None
pyarrow : None
pytables : None
pyxlsb : None
s3fs : None
scipy : None
sqlalchemy : 1.3.19
tables : None
tabulate : None
xarray : None
xlrd : 1.2.0
xlwt : None
numba : None
The text was updated successfully, but these errors were encountered: