GroupbyRolling aggregate error introduced by bottleneck #26156
Comments
|
MeanRound is not defined |
|
edited just now |
|
this is user error; you are performing a mean on a series, yielding a scalar (a float), so you need to use |
|
@jreback, can you help me understand why My user experience was that I added the I totally understand the "user error" aspect, but perhaps my code should have thrown the same error even if bottleneck is not installed, instead of giving me what I want? |
|
you would have to debug inside the function |
|
you're right -- I could have isolated the issue more efficiently. My thought was that the traceback would have something related to numpy or bottleneck...? AttributeError Traceback (most recent call last)
~\AppData\Local\Continuum\miniconda3\envs\azure_automl\lib\site-packages\pandas\core\groupby\groupby.py in apply(self, func, *args, **kwargs)
688 try:
--> 689 result = self._python_apply_general(f)
690 except Exception:
~\AppData\Local\Continuum\miniconda3\envs\azure_automl\lib\site-packages\pandas\core\groupby\groupby.py in _python_apply_general(self, f)
706 keys, values, mutated = self.grouper.apply(f, self._selected_obj,
--> 707 self.axis)
708
~\AppData\Local\Continuum\miniconda3\envs\azure_automl\lib\site-packages\pandas\core\groupby\ops.py in apply(self, f, data, axis)
189 group_axes = _get_axes(group)
--> 190 res = f(group)
191 if not _is_indexed_like(res, group_axes):
~\AppData\Local\Continuum\miniconda3\envs\azure_automl\lib\site-packages\pandas\core\window.py in f(x, name, *args)
797
--> 798 return x.apply(name, *args, **kwargs)
799
~\AppData\Local\Continuum\miniconda3\envs\azure_automl\lib\site-packages\pandas\core\window.py in apply(self, func, raw, args, kwargs)
1702 return super(Rolling, self).apply(
-> 1703 func, raw=raw, args=args, kwargs=kwargs)
1704
~\AppData\Local\Continuum\miniconda3\envs\azure_automl\lib\site-packages\pandas\core\window.py in apply(self, func, raw, args, kwargs)
1011 return self._apply(f, func, args=args, kwargs=kwargs,
-> 1012 center=False, raw=raw)
1013
~\AppData\Local\Continuum\miniconda3\envs\azure_automl\lib\site-packages\pandas\core\window.py in _apply(self, func, name, window, center, check_minp, **kwargs)
879 else:
--> 880 result = calc(values)
881
~\AppData\Local\Continuum\miniconda3\envs\azure_automl\lib\site-packages\pandas\core\window.py in calc(x)
873 return func(x, window, min_periods=self.min_periods,
--> 874 closed=self.closed)
875
~\AppData\Local\Continuum\miniconda3\envs\azure_automl\lib\site-packages\pandas\core\window.py in f(arg, window, min_periods, closed)
1008 arg, window, minp, indexi,
-> 1009 closed, offset, func, raw, args, kwargs)
1010
c:\Users\anders.swanson\Documents\attrition\pandas\_libs\window.pyx in pandas._libs.window.roll_generic()
<ipython-input-13-bffd2448d694> in MeanRound(x)
2 # return np.round(x.mean(),4)
----> 3 return x.mean().round(4) |
|
as i said your code is incorrect; it happens to work because a np.float64 has a round method; if there is a float returned it will fail |
|
thanks for staying with me here.
am i correct in that my general takeaway should be to:
|
|
you shouldn’t use custom functions as all |
|
the real source of this "user error" is that |
|
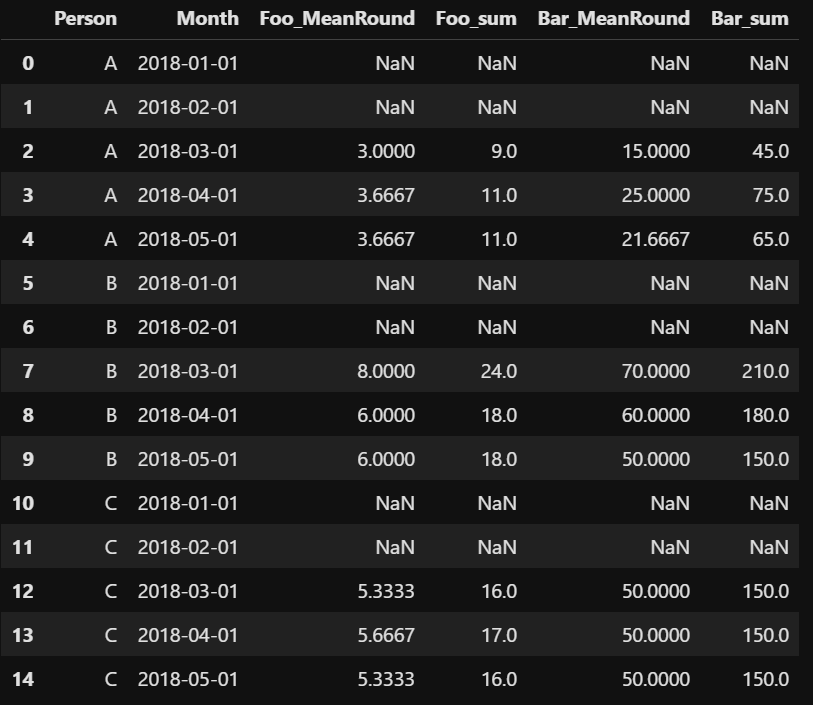
Sidebar the real reason I'm using a custom function is because of this deprecated functionality (see #18366). The workaround is to use custom function simply so that I can flatten resulting hierarchical column index into meaningful column names (see below). If I use lambda functions, I've lost the ability to programmatically name the columns. df_rolls = (df
.sort_values(by=['Month', 'Person'], ascending=True)
.set_index(['Month'])
.groupby(['Person'])
.rolling(3, min_periods=3)
)
def MeanRound(x):
return np.round(x.mean(), 4)
df = df_rolls.agg([MeanRound, 'sum'])
df.columns = ["_".join(x) for x in df.columns.ravel()]
df.reset_index(drop= False, inplace = True)
df
|
Code Sample, a copy-pastable example if possible
this works without bottleneck installed but throws this error:
# AttributeError: 'float' object has no attribute 'round'Problem description
my intention is to compute rolling a rolling mean and sum on multiple columns at once (see below). I was using agg because it allows for multiple functions at once.
Expected Output
I was able get a workaround with apply (even though
.transform()isn't implemented forRollingGroupby?)Output of
pd.show_versions()[paste the output of
pd.show_versions()here below this line]before bottleneck
after bottleneck
The text was updated successfully, but these errors were encountered: