- Release Signoff Checklist
- Summary
- Motivation
- Proposal
- Design Details
- Production Readiness Review Questionnaire
- Implementation History
- Drawbacks
- Alternatives
Items marked with (R) are required prior to targeting to a milestone / release.
- (R) Enhancement issue in release milestone, which links to KEP dir in kubernetes/enhancements (not the initial KEP PR)
- (R) KEP approvers have approved the KEP status as
implementable - (R) Design details are appropriately documented
- (R) Test plan is in place, giving consideration to SIG Architecture and SIG Testing input
(including test refactors)
- e2e Tests for all Beta API Operations (endpoints)
- (R) Ensure GA e2e tests for meet requirements for Conformance Tests
- (R) Minimum Two Week Window for GA e2e tests to prove flake free
- (R) Graduation criteria is in place
- (R) all GA Endpoints must be hit by Conformance Tests
- (R) Production readiness review completed
- (R) Production readiness review approved
- "Implementation History" section is up-to-date for milestone
- User-facing documentation has been created in kubernetes/website, for publication to kubernetes.io
- Supporting documentation—e.g., additional design documents, links to mailing list discussions/SIG meetings, relevant PRs/issues, release notes
Allow to dynamically expand the number of IPs available for Services.
Services are an abstract way to expose an application running on a set of Pods. Some type of Services: ClusterIP, NodePort and LoadBalancer use cluster-scoped virtual IP address, ClusterIP. Across your whole cluster, every Service ClusterIP must be unique. Trying to create a Service with a specific ClusterIP that has already been allocated will return an error.
Current implementation of the Services IP allocation logic has several limitations:
- users can not resize or increase the ranges of IPs assigned to Services, causing problems when there are overlapping networks or the cluster run out of available IPs.
- the Service IP range is not exposed, so it is not possible for other components in the cluster to consume it
- the configuration is per apiserver, there is no consensus and different apiservers can fight and delete others IPs.
- the allocation logic is racy, with the possibility of leaking ClusterIPs kubernetes/kubernetes#87603
- the size of the Service Cluster CIDR, for IPv4 the prefix size is limited to /12, however, for IPv6 it is limited to /112 or fewer. This restriction is causing issues for IPv6 users, since /64 is the standard and minimum recommended prefix length
- only is possible to use reserved a range of Service IP addresses using the feature gate "keps/sig-network/3070-reserved-service-ip-range" kubernetes/kubernetes#95570
Implement a new allocation logic for Services IPs that:
- scales well with the number of reservations
- the number of allocation is tunable
- is completely backwards compatible
- Any change unrelated to Services
- Any generalization of the API model that can evolve onto something different, like an IPAM API, or collide with existing APIs like Ingress and GatewayAPI.
- NodePorts use the same allocation model than ClusterIPs, but it is totally out of scope of this KEP. However, this KEP can be a proof that a similar model will work for NodePorts too.
- Change the default IPFamily used for Services IP allocation, the defaulting depends on the services.spec.IPFamily and services.spec.IPFamilyPolicy, a simple webhook or an admission plugin can set this fields to the desired default, so the allocation logic doesn't have to handle it.
- Removing the apiserver flags that define the service IP CIDRs, though that may be possible in the future.
- Any admin or cluster wide process related to Services, like automating the default Service CIDR range, though, this KEP will implement the behaviours and primitives necessaries to perform those kind of operations automatically.
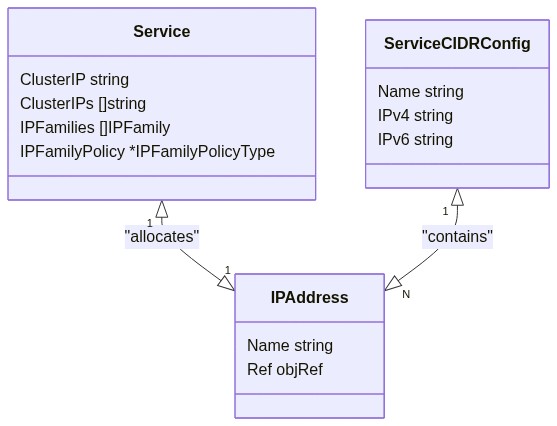
The proposal is to implement a new allocator logic that uses 2 new API Objects: ServiceCIDR and IPAddress, and allow users to dynamically increase the number of Services IPs available by creating new ServiceCIDRs.
The new allocator will be able to "automagically" consume IPs from any ServiceCIDR available, we can think about this model, as the same as adding more disks to a Storage system to increase the capacity.
To simplify the model, make it backwards compatible and to avoid that it can evolve into something different and collide with other APIs, like Gateway APIs, we are adding the following constraints:
- a ServiceCIDR will be immutable after creation.
- a ServiceCIDR can only be deleted if there are no Service IP associated to it (enforced by finalizer).
- there can be overlapping ServiceCIDRs.
- the apiserver will periodically ensure that a "default" ServiceCIDR exists to cover the service CIDR flags and the "kubernetes.default" Service.
- any IPAddress existing in a cluster has to belong to a Service CIDR defined by a ServiceCIDR.
- any Service with a ClusterIP assigned is expected to have always a IPAddress object associated.
- a ServiceCIDR which is being deleted can not be used to allocate new IPs
This creates a 1-to-1 relation between Service and IPAddress, and a 1-to-N relation between the ServiceCIDRs defined by the ServiceCIDR and IPAddress. It is important to clarify that overlapping ServiceCIDR are merged in memory, an IPAddress doesn't come from a specific ServiceCIDR object, but "any ServiceCIDR that includes that IP"
The new allocator logic can be used by other APIs, like Gateway API.
The new well defined behaviors and objects implemented will allow future developments to perform admin and cluster wide operations on the Service ranges.
As a Kubernetes user I want to be able to dynamically increase the number of IPs available for Services.
As a Kubernetes admin I want to have a process that allows me to renumber my Services IPs.
As a Kubernetes developer I want to be able to know the current Service IP range and the IP addresses allocated.
As a Kubernetes admin that wants to use IPv6, I want to be able to follow the IPv6 address planning best practices, being able to assign /64 prefixes to my end subnets.
Current API machinery doesn't consider transactions, Services API is kind of special in this regard since already performs allocations inside the Registry pipeline using the Storage to keep consistency on an Obscure API Object that stores the bitmap with the allocations. This proposal still maintains this behavior, but instead of modifying the shared bitmap, it will create a new IPAddress object.
Changing service IP allocation to be async with regards to the service creation would be a MAJOR semantic change and would almost certainly break clients.
Cross validation of Objects is not common in the Kubernetes API, sig-apimachinery should verify that a bad precedent is not introduced.
Current Kubernetes cluster have a very static network configuration, allowing to expand the Service IP ranges will give more flexibility to users, with the risk of having problematic or incongruent network configurations with overlapping. But this is not really a new problem, users need to do a proper network planning before adding new ranges to the Service IP pool.
Service implementations,like kube-proxy, can be impacted if they were doing assumptions about the ranges assigned to the Services. Those implementations should implement logic to watch the configured Service CIDRs.
Kubernetes DNS implementations, like CoreDNS, need to know the Service CIDRs for PTR lookups (and to know which PTR look ups they are NOT authoritative on). Those implementations should be impacted, but they can also benefit from the new API to automatically configure the Service CIDRs.
Kubernetes Services need to be able to dynamically allocate resources from a predefined range/pool for ClusterIPs.
ClusterIP is the IP address of the service and is usually assigned randomly. If an address is specified manually, is in-range, and is not in use, it will be allocated to the service; otherwise creation of the service will fail. The Service ClusterIP range is defined in the kube-apiserver with the following flags:
--service-cluster-ip-range string
A CIDR notation IP range from which to assign service cluster IPs. This must not overlap with any IP ranges assigned to nodes or pods. Max of two dual-stack CIDRs is allowed.
And in the controller-manager (this is required for the node-ipam controller to avoid overlapping with the podCIDR ranges):
--service-cluster-ip-range string
CIDR Range for Services in cluster. Requires --allocate-node-cidrs to be true
The allocator is implemented using a bitmap that is serialized and stored in an "opaque" API object.
To avoid leaking resources, the apiservers run a repair loop that keep the bitmaps in sync with the current Services allocated IPs.
The order of the IP families defined in the service-cluster-ip-range flag defines the primary IP family used by the allocator. This default IP family is used in cases where a Service creation doesn't provide the necessary information, defaulting the Service to Single Stack with an IP chosen from the default IP family defined.
The current implementation doesn't guarantee consistency for Service IP ranges and default IP families across multiple apiservers, see kubernetes/kubernetes#114743.
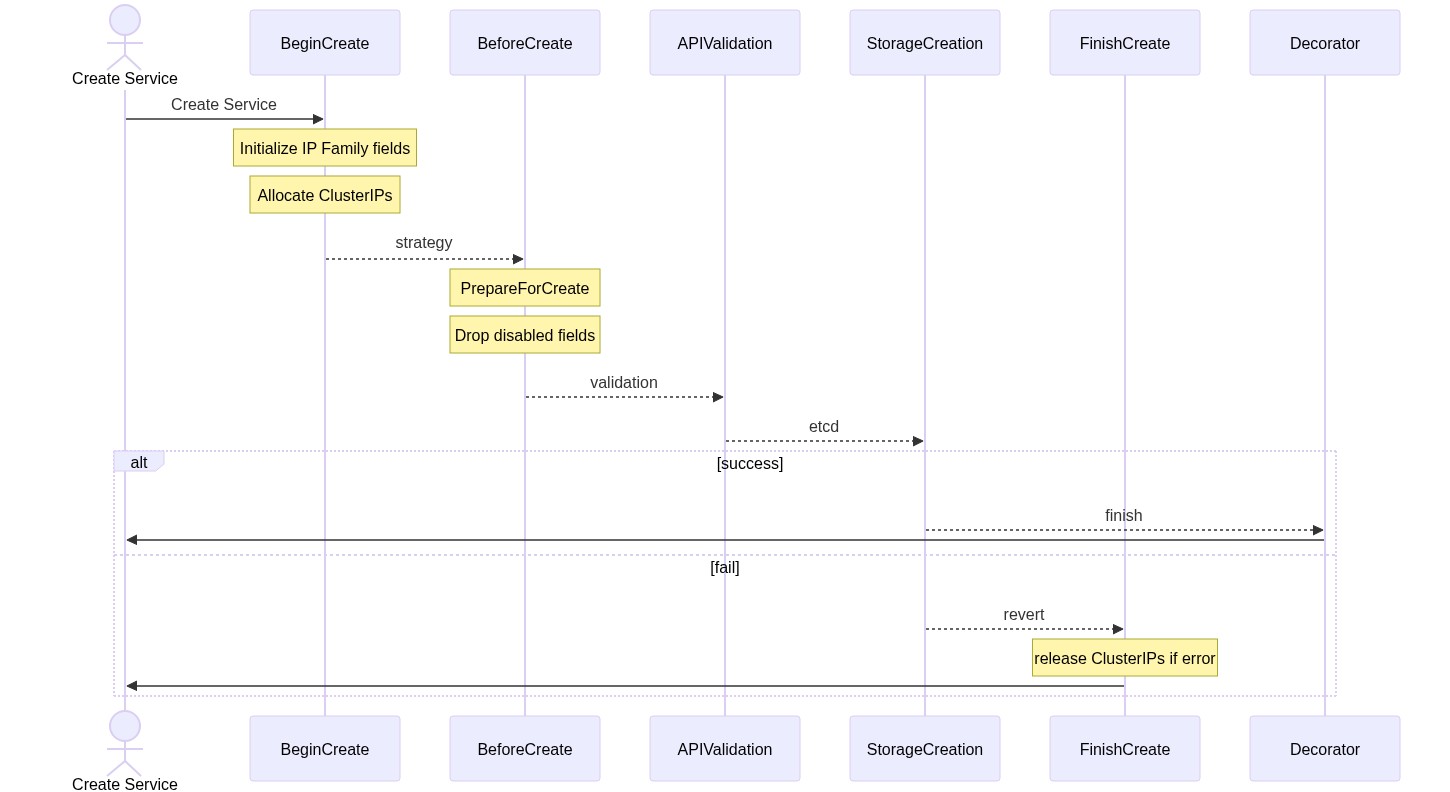
The new allocation mode requires:
- 2 new API objects ServiceCIDR and IPAddress in the group
networking.k8s.io, see https://groups.google.com/g/kubernetes-sig-api-machinery/c/S0KuN_PJYXY/m/573BLOo4EAAJ. The ServiceCIDR will be protected with a finalizer, the IPAddress object doesn't need a finalizer because the APIserver always release and delete the IPAddress after the Service has been deleted. - 1 new allocator implementing current
allocator.Interface, that runs in each apiserver, and uses the new ServiceCIDRs objects to allocate IPs for Services. - 1 new repair loop that runs in the apiserver that reconciles the Services with the IPAddresses: repair Services, garbage collecting orphan IPAddresses and handle the upgrade from the old allocators.
- 1 new controller that handles the bootstrap process and the ServiceCIDR object. This controllers participates on the ServiceCIDR deletion, guaranteeing that the existing IPaddresses always have a ServiceCIDR associated.
Currently, the Service CIDRs are configured independently in each kube-apiserver using flags. During the bootstrap process, the apiserver uses the first IP of each range to create the special "kubernetes.default" Service. It also starts a reconcile loop, that synchronize the state of the bitmap used by the internal allocators with the assigned IPs to the Services. This "kubernetes.default" Service is never updated, the first apiserver wins and assigns the ClusterIP from its configured service-ip-range, other apiservers with different ranges will not try to change the IP. If the apiserver that created the Service no longer works, the admin has to delete the Service so others apiservers can create it with its own ranges.
With current implementation, each kube-apiserver can boot with different ranges configured without errors, but the cluster will not work correctly, see kubernetes/kubernetes#114743. There is no conflict resolution, each apiserver keep writing and deleting others apiservers allocator bitmap and Services.
In order to be completely backwards compatible, the bootstrap process will remain the same, the
difference is that instead of creating a bitmap based on the flags, it will create a new
ServiceCIDR object from the flags (flags configuration removal is out of scope of this KEP)
with a special well-known name kubernetes.
The new bootstrap process will be:
at startup:
read_flags
if invalid flags
exit
run default-service-ip-range controller
run kubernetes.default service loop (it uses the first ip from the subnet defined in the flags)
run service-repair loop (reconcile services, ipaddresses)
run apiserver
controller:
if ServiceCIDR `kubernetes` does not exist
create it and create the kubernetes.default service (avoid races)
else
keep watching to handle finalizers and recreate if needed
All the apiservers will be synchronized on the ServiceCIDR and default Service created by the first to win. Changes on the configuration imply manual removal of the ServiceCIDR and default Service, automatically the rest of the apiservers will race and the winner will set the configuration of the cluster.
This behavior align with current behavior of kubernetes.default, that it makes it consistent and easier to think about, allowing future developments to use it to implement more complex operations at the admin cluster level.
The kubernetes.default Service is expected to be covered by a valid range. Each apiserver
ensure that a ServiceCIDR object exists to cover its own flag-defined ranges. If someone were to force-delete
the ServiceCIDR covering kubernetes.default it would be treated the same as before, any apiserver will try
to recreate the Service from its configured default Service CIDR flag-defined range.
This well-known an establish behavior can allow administrators to replace the kubernetes.default by a
series of operations, per example:
- Initial state: 2 kube-apiservers with default ServiceCIDR 10.0.0.0/24
- Apiservers will create the
kubernetes.defaultService with ClusterIP 10.0.0.1. - Upgrade kube-apiservers and replace the service-cidr flag to 192.168.0.0/24
- Delete the ServiceCIDRs objects and the
kubernetes.defaultService. - The kube-apiserver will recreate the
kubernetes.defaultwith IP 192.168.0.1.
Note this can also be used to switch the IP family of the cluster.
When a a new Service is going to be created and already has defined the ClusterIPs, the allocator will just try to create the corresponding IPAddress objects, any error creating the IPAddress object will cause an error on the Service creation. The allocator will also set the reference to the Service on the IPAddress object.
The new allocator will have a local list with all the Service CIDRs and IPs already allocated, so it will have to check just for one free IP in any of these ranges and try to create the object. There can be races with 2 allocators trying to allocate the same IP, but the storage guarantees the consistency and the first will win, meanwhile the other will have to retry.
Another racy situation is when the allocator is full and an IPAddress is deleted but the allocator takes some time to receive the notification. One solution can be to perform a List to obtain current state, but it will be simpler to just fail to create the Service and ask the user to try to create the Service again.
If the apiserver crashes during a Service create operation, the IPAddress is allocated but the
Service is not created, the IPaddress will be orphan. To avoid leaks, a controller will use the
metadata.creationTimestamp field to detect orphan objects and delete them.
There is going to be a controller to avoid leaking resources:
- checking that the corresponding parentReference on the IPAddress match the corresponding Service
- cleaning all IPAddress without an owner reference or, if the time since it was created is greater than 60 seconds (default timeout value on the kube-apiserver )
In keps/sig-network/3070-reserved-service-ip-range a new feature was introduced that allow to prioritize one part of the Service CIDR for dynamically allocation, the range size for dynamic allocation depends ont the size of the CIDR.
The new allocation logic has to be compatible with current implementation.
Since we have to maintain 3 relationships Services, ServiceCIDRs and IPAddresses, we should be able to handle edge cases and race conditions.
- Valid Service and IPAddress without ServiceCIDR:
This situation can happen if a user forcefully delete the ServiceCIDR, it can be recreated for the "default" ServiceCIDRs because the information is in the apiserver flags, but for other ServiceCIDRs that information is no longer available.
Another possible situation is when one ServiceCIDR has been deleted, but the information takes too long to reach one of the apiservers, its allocator will still consider the range valid and may allocate one IP from there. To mitigate this problem, we'll set a grace period of 60 seconds on the servicecidrconfig controller to remove the finalizer, if an IP address is created during this time we'll be able to block the deletion and inform the user.
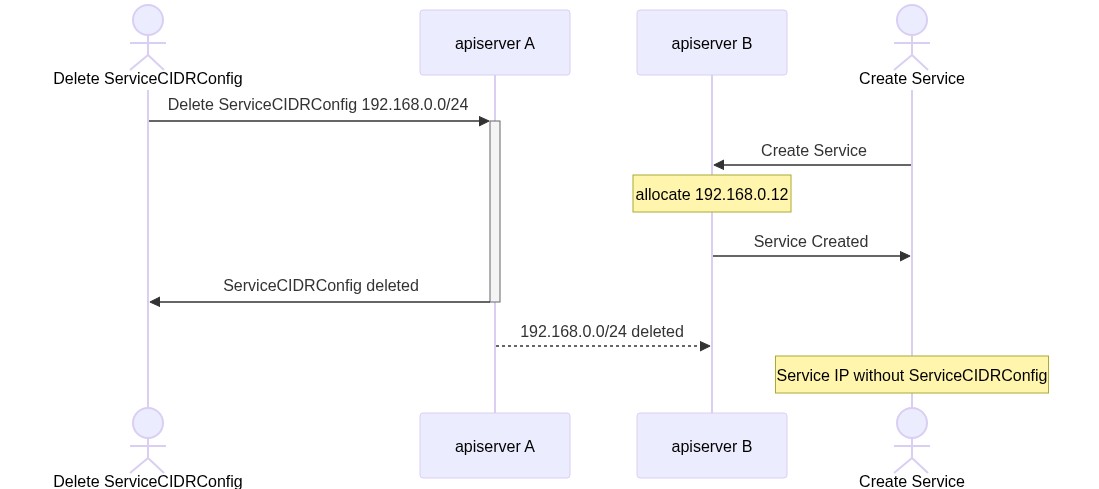
For any Service and IPAddress that doesn't belong to a ServiceCIDR the controller will raise an event informing the user, keeping the previous behavior
// cluster IP is out of range
c.recorder.Eventf(&svc, nil, v1.EventTypeWarning, "ClusterIPOutOfRange", "ClusterIPAllocation", "Cluster IP [%v]:%s is not within the service CIDR %s; please recreate service",- Valid Service and ServiceCIDR but not IPAddress
It can happen that an user forcefully delete an IPAddress, in this case, the controller will regenerate the IPAddress, as long as a valid ServiceCIDR covers it.
During this time, there is a chance that an apiserver tries to allocate this IPAddress, with a possible situation where 2 Services has the same IPAddress. In order to avoid it, the Allocator will not delete an IP from its local cache until it verifies that the consumer associated to that IP has been deleted too.
- Valid IPAddress and ServiceCIDR but no Service
The IPAddress will be deleted and an event generated if the controller determines that the IPAddress is orphan (see Allocator section)
One of the most common problems users may have is how to scale up or scale down their Service CIDRs.
Let's see an example on how these operations will be implemented.
Assume we have configured a Service CIDR 10.0.0.0/24 and its fully used, we can:
- Add another /24 Service CIDR 10.0.1.0/24 and keep the previous one
- Add an overlapping larger Service CIDR 10.0.0.0/23
After 2., the user can now remove the first /24 Service CIDR, since the new Service CIDR covers all the existing IP Addresses
The same applies for scaling down, meanwhile the new Service CIDR contains all the existing IPAddresses, the old Service CIDR will be safely deleted.
However, there can be a race condition during the operation of scaling down, since the propagation of the deletion can take some time, one allocator can successfully allocate an IP address out of new Service CIDR (but still inside of the old Service CIDR).
There is one controller that will periodically check that the 1-on-1 relation between IPAddresses and Services is correct, and will start sending events to warn the user that it has to fix/recreate the corresponding Service, keeping the same behavior that exists today.
// ServiceCIDR defines a range of IP addresses using CIDR format (e.g. 192.168.0.0/24 or 2001:db2::/64).
// This range is used to allocate ClusterIPs to Service objects.
type ServiceCIDR struct {
metav1.TypeMeta `json:",inline"`
// Standard object's metadata.
// More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#metadata
// +optional
metav1.ObjectMeta `json:"metadata,omitempty" protobuf:"bytes,1,opt,name=metadata"`
// spec is the desired state of the ServiceCIDR.
// More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#spec-and-status
// +optional
Spec ServiceCIDRSpec `json:"spec,omitempty" protobuf:"bytes,2,opt,name=spec"`
// status represents the current state of the ServiceCIDR.
// More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#spec-and-status
// +optional
Status ServiceCIDRStatus `json:"status,omitempty" protobuf:"bytes,3,opt,name=status"`
}
// ServiceCIDRSpec describe how the ServiceCIDR's specification looks like.
type ServiceCIDRSpec struct {
// CIDRs defines the IP blocks in CIDR notation (e.g. "192.168.0.0/24" or "2001:db8::/64")
// from which to assign service cluster IPs. Max of two CIDRs is allowed, one of each IP family.
// This field is immutable.
// +optional
// +listType=atomic
CIDRs []string `json:"cidrs,omitempty" protobuf:"bytes,1,opt,name=cidrs"`
}
// IPAddress represents an IP used by Kubernetes associated to an ServiceCIDR.
// The name of the object is the IP address in canonical format.
type IPAddress struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty"`
Spec IPAddressSpec `json:"spec,omitempty"`
}
// IPAddressSpec describe the attributes in an IP Address,
type IPAddressSpec struct {
// ParentRef references the resources (usually Services) that a IPAddress wants to be attached to.
ParentRef ParentReference
}
type ParentReference struct {
// Group is the group of the referent.
Group string
// Resource is resource of the referent.
Resource string
// Namespace is the namespace of the referent
Namespace string
// Name is the name of the referent
Name string
}A new allocator will be implemented that implements the current Allocator interface in the apiserver.
// Interface manages the allocation of IP addresses out of a range. Interface
// should be threadsafe.
type Interface interface {
Allocate(net.IP) error
AllocateNext() (net.IP, error)
Release(net.IP) error
ForEach(func(net.IP))
CIDR() net.IPNet
IPFamily() api.IPFamily
Has(ip net.IP) bool
Destroy()
EnableMetrics()
// DryRun offers a way to try operations without persisting them.
DryRun() Interface
}This allocator will have an informer watching Services, ServiceCIDRs and IPAddresses, so it can have locally the information needed to assign new IP addresses to Services.
IPAddresses can only be allocated from ServiceCIDRs that are available and not being deleted.
The uniqueness of an IPAddress is guaranteed by the apiserver, since trying to create an IP address that already exist will fail.
The allocator will set finalizer on the IPAddress created to avoid that there are Services without the corresponding IP allocated.
It also will add a reference to the Service the IPAddress is associated.
This is a very core and critical change, it has to be thoroughly tested on different layers:
API objects must have unit tests for defaulting and validation and integration tests exercising the different operations and fields permutations, with both positive and negative cases: Special attention to cross-reference validation problems, like create IPAddress reference wrong ServiceCIDR or invalid or missing
Controllers must have unit tests and integration tests covering all possible race conditions.
Since this is an API based feature, integration test must be added covering the user stories defined in the KEP.
E2E must be added in order for components that depend on Services, like kube-proxy, to evaluate its compatibility.
[x] I/we understand the owners of the involved components may require updates to existing tests to make this code solid enough prior to committing the changes necessary to implement this enhancement.
- cmd/kube-apiserver/app/options/validation_test.go: 06/02/23 - 99.1
- pkg/apis/networking/validation/validation_test.go: 06/02/23 - 91.7
- pkg/controller/servicecidrs/servicecidrs_controller.go: 11/06/24 - 64.3
- pkg/controlplane/instance_test.go: 06/02/23 - 49.7
- pkg/controlplane/controller/defaultservicecidr/default_servicecidr_controller.go: 11/06/24 - 43.3
- pkg/printers/internalversion/printers_test.go: 06/02/23 - 49.7
- pkg/registry/core/service/ipallocator/bitmap_test.go: 06/02/23 - 86.9
- pkg/registry/core/service/ipallocator/cidrallocator_test.go: 11/06/24 - 69.3
- pkg/registry/core/service/ipallocator/ipallocator_test.go: 11/06/24 - 80.1
- pkg/registry/core/service/ipallocator/metrics_test.go: 11/06/24 - 100
- pkg/registry/core/service/ipallocator/controller/metrics_test.go: 11/06/24 - 100
- pkg/registry/core/service/ipallocator/controller/repair_test.go: 11/06/24 - 74.4
- pkg/registry/core/service/ipallocator/controller/repairip_test.go: 11/06/24 - 47.6
- pkg/registry/networking/ipaddress/strategy_test.go: 11/06/24 - 77.8
- staging/src/k8s.io/kubectl/pkg/describe/describe_test.go: 06/02/23 - 49.7
There will be added tests to verify:
- API servers using the old and new allocators at same time
- API server upgrade from old to new allocator
- ServicesCIDRs resizing
- ServiceCIDR without the IPv6 limitation size
- Default ServiceCIDR can be migrated to a new one
- ServiceCIDR can not leave orhpan IPAddress objects
Files:
- test/integration/controlplane/synthetic_controlplane_test.go
- test/integration/servicecidr/allocator_test.go
- test/integration/servicecidr/migration_test.go
- test/integration/servicecidr/servicecidr_test.go
- test/integration/servicecidr/feature_enable_disable_test.go
- test/integration/servicecidr/perf_test.go
Links:
https://storage.googleapis.com/k8s-triage/index.html?test=servicecidr%7Csynthetic_controlplane_test
e2e tests validate that components that depend on Services are able to use the new ServiceCIDR ranges allocated.
https://testgrid.k8s.io/kops-misc#kops-aws-sig-network-beta
In addition to the specific e2e test that validate the new functionality of allowing to add new ServiceCIDRs and create new Services using the IPs of the new range, all the existing e2e tests that exercises Services in one way or another are also exercising the new APIs.
If we take a job of an execution of any job with the feature enabled, per example, https://storage.googleapis.com/kubernetes-ci-logs/logs/ci-kubernetes-network-kind-alpha-beta-features/1866163383959556096/artifacts/kind-control-plane/pods/kube-system_kube-apiserver-kind-control-plane_89ea5ffb5eb9e46fc7a038252629d04c/kube-apiserver/0.log , we can see the ServiceCIDR and IPAddress objects are constantly exercised:
$ grep -c networking.k8s.io/v1beta1/servicecidrs 0.log
553
$ grep -c networking.k8s.io/v1beta1/ipaddresses 0.log
400- Feature implemented behind a feature flag
- Initial unit, integration and e2e tests completed and enabled
- Only basic functionality e2e tests implemented
- Define "Service IP Reservation" implementation
- API stability, no changes on new types and behaviors:
- ServiceCIDR immutability
- default IPFamily
- two or one IP families per ServiceCIDR
- Gather feedback from developers and users
- Document and add more complex testing scenarios: scaling out ServiceCIDRs, ...
- Additional tests are in Testgrid and linked in KEP
- Scale test to O(10K) services and O(1K) ranges
- Improve performance on the allocation logic, O(1) for allocating a free address
- Allowing time for feedback
- examples of real-world usage:
- It is available in GKE https://cloud.google.com/kubernetes-engine/docs/how-to/use-beta-apis since 1.31 and used in production clusters (numbers can not be disclosed)
- Non-GKE blog about how to use the ServiceCIDR feature in GKE.
- It can be used by OSS users with installers that allow to set the feature gates and enable the beta apis, automated testing with kops, see kubernetes/test-infra#33864 and e2e tests section.
- It is being tested by the community spidernet-io/spiderpool#4089 (comment) since it went beta in 1.31.
- It is available in GKE https://cloud.google.com/kubernetes-engine/docs/how-to/use-beta-apis since 1.31 and used in production clusters (numbers can not be disclosed)
- More rigorous forms of testing—e.g., downgrade tests and scalability tests
- It is tested internally in GKE as part of the release.
- It will inherit all the project testing (scalability, e2e, ...) after being graduated.
- Allowing time for feedback
- The feature was beta in 1.31, it has been tested by different projects and enabled in one platform with only one bug reported.
Note: Generally we also wait at least two releases between beta and GA/stable, because there's no opportunity for user feedback, or even bug reports, in back-to-back releases.
For non-optional features moving to GA, the graduation criteria must include conformance tests.
The source of truth are the IPs assigned to the Services, both the old and new methods have reconcile loops that rebuild the state of the allocators based on the assigned IPs to the Services, this allows to support upgrades and skewed clusters.
Clusters running with the new allocation model will not keep running the reconcile loops that keep the bitmap used by the allocators.
Since the new allocation model will remove some of the limitations of the current model, skewed versions and downgrades can only work if the configurations are fully compatible, per example, current CIDRs are limited to a /112 max for IPv6, if an user configures a /64 to their IPv6 subnets in the new model, and IPs are assigned out of the first /112 block, the old allocator based in bitmap will not be able to use those IPs creating an inconsistency in the cluster.
It will be required that those Services are recreated to get IP addresses inside the configured ranges, for consistency, but there should not be any functional problem in the cluster if the Service implementation (kube-proxy, ...) is able to handle those IPs.
Example:
- flags set to 10.0.0.0/20
- upgrade to N+1 with alpha gate
- apiserver create a default ServiceCIDR object for 10.0.0.0/20
- user creates a new ServiceCIDR for 192.168.1.0/24
- create a Service which gets 192.168.1.1
- rollback or disable the gate
- the apiserver repair loops will generate periodic events informing the user that the Service with the IP allocated is not within the configured range
One of the biggest problem when running with skewed apiservers is that each of them will use independent allocators that will rely on the repair loops to reconcile the Services and ClusterIP. This can cause that two Services created in different skewed apiservers, requesting the same ClusterIP, can succeed if the allocation happens before the repair loops run, with the catastrophic result of having two Services with the same ClusterIP.
To avoid this race problem, the new IP allocator will implement a dual-write strategy, creating an IPAddress object and
also allocating the IP in the corresponding bitmap allocator. This behavior will be controlled with a new feature gate,
DisableAllocatorDualWrite, that will be disabled by default until MultiCIDRServiceAllocator is GA.
The next version after MultiCIDRServiceAllocator is GA, all the apiservers will be using the new IP allocator, so
it will be safe to disable the dual-write mode.
| Version | MultiCIDRServiceAllocator | DisableAllocatorDualWrite |
|---|---|---|
| 1.31 | Beta off | Alpha off |
| 1.32 | Beta on | Alpha off |
| 1.33 | GA on (not locked by default) | Beta off |
| 1.34 | GA (lock by default) | GA (not locked by default) |
| 1.35 | GA (there are no bitmaps running) | GA (also delete old bitmap) |
| 1.36 | remove feature gate | GA |
| 1.37 | --- | remove feature gate |
- Feature gate (also fill in values in
kep.yaml)- Feature gate name: MultiCIDRServiceAllocator
- Components depending on the feature gate: kube-apiserver, kube-controller-manager
- Feature gate name: DisableAllocatorDualWrite
- Components depending on the feature gate: kube-apiserver,
- Feature gate name: MultiCIDRServiceAllocator
The time to reuse an already allocated ClusterIP to a Service may be longer, since the ClusterIPs now depend on an IPAddress object that is protected by a finalizer.
The bootstrap logic has been updated to deal with the problem of multiple apiservers with different configurations, making it more flexible and resilient.
If the feature is disabled the old allocator logic will reconcile all the current allocated IPs based on the Services existing on the cluster.
If there are IPAddresses allocated outside of the configured Service IP Ranges in the apiserver flags, the apiserver will generate events referencing the Services using IPs outside of the configured range. The user must delete and recreate these Services to obtain new IPs within the range.
There are controllers that will reconcile the state based on the current created Services, restoring the cluster to a working state.
Tests for feature enablement/disablement are implemented as integration test, see test/integration/servicecidr/feature_enable_disable.go
The feature add new API objects, no new API fields to existing objects are added.
The objects consumed by the cluster components are the Services, and ClusterIP is a field of these objects. Running workloads can not be impacted since the existing Services objects are never mutated.
A rollout failure can impact the new apiserver to not be able to start or the clients not being able to create new Services.
The feature impact the apiserver bootstrap process, specially about the kubernetes.default IP address assignment, in case the apiserver is not able to start after enabling the feature, it is a strong indicated that a rollback is required.
Another metrics that can indicate a rollback are clusterip_allocator.allocation_errors_total, clusterip_repair.ip_errors_total or clusterip_repair.reconcile_errors_total, definitions can be found on
- IP allocator pkg/registry/core/service/ipallocator/metrics.go
- IP repair loop pkg/registry/core/service/ipallocator/controller/metrics.go
There are integration tests these behaviors:
test/integration/servicecidr/allocator_test.go TestSkewedAllocators
- start one apiserver with the feature gate enabled and other with the feature gate disabled
- create 5 Services against each apiserver
- the Services created against the apiserver with the bitmap will not allocate the IPAddresses automatically, but the repair loop of the apiserver with the feature enable must reconcile these new Services and create the IPAddresses
test/integration/servicecidr/allocator_test.go TestMigrateService
- store a Service with ClusterIP directly in etcd
- start an apiserver with the new feature enable
- the reconciler must detect this stored service and create the corresponding IPAddress
test/integration/servicecidr/feature_enable_disable.go TestEnableDisableServiceCIDR
- start apiserver with the feature disabled
- create new services and assert are correct
- shutdown apiserver
- start new apiserver with feature enabled
- create new services and assert previous and new ones are correct
- shutdown apiserver
- start new apiserver with feature disabled
- create new services and assert previous and new ones are correct
Is the rollout accompanied by any deprecations and/or removals of features, APIs, fields of API types, flags, etc.?
No
A group of metrics are added to each new Cluster IP allocators, labeled with the correspoding ServiceCIDR associateed to the allocator:
clusterip_allocator.allocated_ips
clusterip_allocator.available_ips
clusterip_allocator.allocation_total
See IP allocator pkg/registry/core/service/ipallocator/metrics.go for definitions.
Users can also obtain the ServiceCIDR and IPAddress objects that are only available
if the feature is enabled, per each Service with a ClusterIP associated there must be a
corresponding IPAddress object. Per example:
$ kubectl get service kubernetes
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 17d
$ kubectl get ipaddress 10.96.0.1
NAME PARENTREF
10.96.0.1 services/default/kubernetes
All the ServiceCIDRs ranges configured must be present, included those ones created from the
apiserver flags to initialize the cluster, with the special name kubernetes:
$ kubectl get servicecidr
NAME CIDRS AGE
kubernetes 10.96.0.0/28 17d
-
Events
- Event Reason: KubernetesDefaultServiceCIDRError, "The default ServiceCIDR can not be created"
- Event Reason: KubernetesDefaultServiceCIDRError, "The default ServiceCIDR Status can not be set to Ready=True"
- Event Reason: ClusterIPOutOfRange, ClusterIP is not within any configured Service CIDR; please recreate service
- Event Reason: ClusterIPNotAllocated, ClusterIP is not allocated; repairing
- Event Reason: UnknownError, Unable to allocate Cluster IP due to unknown error
- Event Reason: ClusterIPNotAllocated, ClusterIP has a wrong reference; repairing
- Event Reason: ClusterIPAlreadyAllocated, ClusterIP was assigned to multiple services; please recreate service
- Event Reason: IPAddressNotAllocated, IPAddress appears to have been modified, not referencing a Service : cleaning up
- Event Reason: IPAddressNotAllocated, IPAddress appears to have leaked: cleaning up
- Event Reason: IPAddressWrongReference, IPAddress for Service has a wrong reference; cleaning up
-
API .status
- Condition name: ServiceCIDRConditionReady, represents status of a ServiceCIDR that is ready to be used by the apiserver to allocate ClusterIPs for Services.
- Condition reason: ServiceCIDRReasonTerminating, represents a reason where a ServiceCIDR is not ready because it is being deleted.
- 99.9% of ClusterIP allocations per day take less than 500 ms.
- 100% of ClusterIP allocations succeed.
What are the SLIs (Service Level Indicators) an operator can use to determine the health of the service?
- Metrics
- Metric name: ip_errors_total, reconcile_errors_total, allocation_errors_total should be 0 and allocation_duration_seconds should be < 500 ms
- Components exposing the metric: kube-apiserver
Are there any missing metrics that would be useful to have to improve observability of this feature?
Idially we should have metrics to detect overlaps or IP conflicts with the Pods and Nodes network, but this was heavily discussed on the SIG and we concluded that is not possible to get the Pod and Nodes network information reliably, so any metrics of this kind will be misleading.
The kube-controller-manager runs a controller to handle the deletion of ServiceCIDR objects to avoid leaking IP address objects due to admin operations.
See Drawbacks section
When creating a Service this will require to create an IPAddress object, previously we updated a bitmap on etcd, so we keep the number of request but the size of the objects stored is reduced considerably.
See API
No
See Drawbacks, a new IPAddress object will be created by Service.Spec.ClusterIP
Will enabling / using this feature result in increasing time taken by any operations covered by existing SLIs/SLOs?
No
Will enabling / using this feature result in non-negligible increase of resource usage (CPU, RAM, disk, IO, ...) in any components?
The apiservers and kube-controller manager will increase the memory usage because they have to keep a local informer with the new objects ServiceCIDR and IPAddress.
Can enabling / using this feature result in resource exhaustion of some node resources (PIDs, sockets, inodes, etc.)?
No
The feature depends on the API server to work, however, the components consuming the existing objects will be unaffected.
- Can not create Service with ClusterIP
- Detection: via metrics that record errors and latency to allocate an Cluster IP, the allocator also log slow operations in
pkg/registry/core/service/ipallocator/ipallocator.go
- Detection: via metrics that record errors and latency to allocate an Cluster IP, the allocator also log slow operations in
trace := utiltrace.New("allocate dynamic ClusterIP address") defer trace.LogIfLong(500 * time.Millisecond)
- Mitigations: already running workloads will not be affected, if no new services can be created first check if is because there are not available IPs checking the metrics with the number of available IPs
- Diagnostics: The ServiceCIDR object has conditions in state that can help to understand if there is some problems with the available ranges. The kube-apiserve metrics shows the repair IP and ip allocation errors.
- Testing: See integration tests added
This feature contain repair controllers in the apiserver that makes rollbacks safe, as they are able to reconcile the current state.
- Alpha
- KEP (
k/enhancements) update PR(s): - Code (
k/k) update PR(s): - Docs (
k/website) update PR(s):
- KEP (
- Beta
- KEP (
k/enhancements) update PR(s): - Code (
k/k) update PR(s): - Docs (
k/website) update(s):
- KEP (
- Stable
- KEP (
k/enhancements) update PR(s): #4983 - Code (
k/k) update PR(s): kubernetes/kubernetes#128971
- KEP (
The number of etcd objects required scales at O(N) where N is the number of services. That seems reasonable (the largest number of services today is limited by the bitmap size ~32k). etcd memory use is proportional to the number of keys, but there are other objects like Pods and Secrets that use a much higher number of objects. 1-2 million keys in etcd is a reasonable upper bound in a cluster, and this has not a big impact (<10%). The objects described here are smaller than most other Kube objects (especially pods), so the etcd storage size is still reasonable.
xref: Clayton Coleman https://github.com/kubernetes/enhancements/pull/1881/files#r669732012
Several alternatives were proposed in the original PR but discarded by different reasons:
From Daniel Smith:
Each apiserver watches services and keeps an in-memory structure of free IPs. Instead of an allocation table, let's call it a "lock list". It's just a list of (IP, lock > expiration timestamp). When an apiserver wants to do something with an IP, it adds an item > to the list with a timestamp e.g. 30 seconds in the future (we can do this in a way that fails if the item is already there, in which case we abort). Then, we go use it. Then, we let the lock expire. (We can delete the lock early if using the IP fails.) (The above could be optimized in etcd by making an entry per-IP rather than a single list.) So, to make a safe allocation, apiserver comes up with a candidate IP address (either randomly or because the user requested it). Check it against the in-memory structure. If that passes, we look for a lock entry. If none is found, we add a lock entry. Then we use it in a service. Then we delete the lock entry (or wait for it to expire).
Nothing special needs to be done for deletion, I think it's fine if it takes a while for individual apiservers to mark an IP as safe for reuse.
Problem: Strong dependency on etcd
From Tim Hockin:
make IP-allocations real resources. In the limit this would mean potentially 10s of thousands of tiny instances, but they don't change often. This would help in other areas where I want to allow APIs to specify IPs without worrying about hijacking important "real" IPs. I imagine it would work something like PVC<->PV binding. The problem here is that at least service IPs have always been synchronous to CREATE and changing that i a pretty significant behavioral difference thath users WILL be able to observe. I don't think we have any precedent for "nested" transactions on user-visible APIs?
Problem: Incompatible change in behavior.
From Wojtek Tyczynski
keep storing a bitmap in-memory of kube-apiserver (have that propagated via watching Service objects) store just the hash from that bitmap in etcd whenever you want to allocate/release IP: (a) get the current hash from etcd (b) compute the hash from your in-memory representation (c) if those two are not equal, you're not synced - wait/retry/... (d) if they are equal, then if this is incorrect operation against in-memory operation return conflct/bad request/... (e) otherwise, apply in-memory and write to etcd having the current version is precondtion > (as in GuaranteedUpdate)
Problems:
If somehow an inconsistent state gets recorded in etcd, then you're permanently stuck here. And the failure mode is really bad (can't make any more services) and requires etcd-level access to fix. So, this is not a workable solution, I think.
From Antonio Ojea
instead of using a bitmap allocator I've created a new API object that has a set of IPs, so the IPs are tracked in the API object
// IPRangeSpec defines the desired state of IPRange type IPRangeSpec struct { // Range represent the IP range in CIDR format // i.e. 10.0.0.0/16 or 2001:db2::/64 // +kubebuilder:validation:MaxLength=128 // +kubebuilder:validation:MinLength=8 Range string
json:"range,omitempty"
// +optional // Addresses represent the IP addresses of the range and its status. // Each address may be associated to one kubernetes object (i.e. Services) // +listType=set Addresses []string
json:"addresses,omitempty"}
// IPRangeStatus defines the observed state of IPRange type IPRangeStatus struct { // Free represent the number of IP addresses that are not allocated in the Range // +optional Free int64
json:"free,omitempty"
Problems: Updates to the set within the object are problematic and difficult to handle.