diff --git a/solution/0200-0299/0254.Factor Combinations/README.md b/solution/0200-0299/0254.Factor Combinations/README.md
index a4afeff023661..fdad3dc75af46 100644
--- a/solution/0200-0299/0254.Factor Combinations/README.md
+++ b/solution/0200-0299/0254.Factor Combinations/README.md
@@ -20,7 +20,8 @@ tags:
例如:
-8 = 2 x 2 x 2;
+
+8 = 2 x 2 x 2;
= 2 x 4.
请实现一个函数,该函数接收一个整数 n 并返回该整数所有的因子组合。
@@ -34,18 +35,21 @@ tags:
示例 1:
-输入: 1
+
+输入: 1
输出: []
示例 2:
-输入: 37
+
+输入: 37
输出: []
示例 3:
-输入: 12
+
+输入: 12
输出:
[
[2, 6],
@@ -55,7 +59,8 @@ tags:
示例 4:
-输入: 32
+
+输入: 32
输出:
[
[2, 16],
@@ -67,6 +72,14 @@ tags:
]
+
+
+提示:
+
+
+
## 解法
diff --git a/solution/0200-0299/0262.Trips and Users/README_EN.md b/solution/0200-0299/0262.Trips and Users/README_EN.md
index 9a6ba0f585bbb..bc65cecf1beeb 100644
--- a/solution/0200-0299/0262.Trips and Users/README_EN.md
+++ b/solution/0200-0299/0262.Trips and Users/README_EN.md
@@ -55,7 +55,7 @@ banned is an ENUM (category) type of ('Yes', 'No').
The cancellation rate is computed by dividing the number of canceled (by client or driver) requests with unbanned users by the total number of requests with unbanned users on that day.
-Write a solution to find the cancellation rate of requests with unbanned users (both client and driver must not be banned) each day between "2013-10-01" and "2013-10-03". Round Cancellation Rate to two decimal points.
+Write a solution to find the cancellation rate of requests with unbanned users (both client and driver must not be banned) each day between "2013-10-01" and "2013-10-03" with at least one trip. Round Cancellation Rate to two decimal points.
Return the result table in any order.
diff --git a/solution/0700-0799/0720.Longest Word in Dictionary/README.md b/solution/0700-0799/0720.Longest Word in Dictionary/README.md
index 2b5851f0e2a22..bf15fcb915ab3 100644
--- a/solution/0700-0799/0720.Longest Word in Dictionary/README.md
+++ b/solution/0700-0799/0720.Longest Word in Dictionary/README.md
@@ -41,7 +41,7 @@ tags:
输入:words = ["a", "banana", "app", "appl", "ap", "apply", "apple"]
输出:"apple"
-解释:"apply" 和 "apple" 都能由词典中的单词组成。但是 "apple" 的字典序小于 "apply"
+解释:"apply" 和 "apple" 都能由词典中的单词组成。但是 "apple" 的字典序小于 "apply"
diff --git a/solution/0700-0799/0722.Remove Comments/README.md b/solution/0700-0799/0722.Remove Comments/README.md
index 8fefc8317cb69..8ab1837937bdf 100644
--- a/solution/0700-0799/0722.Remove Comments/README.md
+++ b/solution/0700-0799/0722.Remove Comments/README.md
@@ -59,20 +59,20 @@ tags:
解释: 示例代码可以编排成这样:
/*Test program */
int main()
-{
- // variable declaration
+{
+ // variable declaration
int a, b, c;
/* This is a test
- multiline
- comment for
+ multiline
+ comment for
testing */
a = b + c;
}
第 1 行和第 6-9 行的字符串 /* 表示块注释。第 4 行的字符串 // 表示行注释。
-编排后:
+编排后:
int main()
-{
-
+{
+
int a, b, c;
a = b + c;
}
diff --git a/solution/0700-0799/0722.Remove Comments/README_EN.md b/solution/0700-0799/0722.Remove Comments/README_EN.md
index bbb95fdbaccea..ee27b0a2e666c 100644
--- a/solution/0700-0799/0722.Remove Comments/README_EN.md
+++ b/solution/0700-0799/0722.Remove Comments/README_EN.md
@@ -58,20 +58,20 @@ tags:
Explanation: The line by line code is visualized as below:
/*Test program */
int main()
-{
- // variable declaration
+{
+ // variable declaration
int a, b, c;
/* This is a test
- multiline
- comment for
+ multiline
+ comment for
testing */
a = b + c;
}
The string /* denotes a block comment, including line 1 and lines 6-9. The string // denotes line 4 as comments.
The line by line output code is visualized as below:
int main()
-{
-
+{
+
int a, b, c;
a = b + c;
}
diff --git a/solution/0700-0799/0727.Minimum Window Subsequence/README_EN.md b/solution/0700-0799/0727.Minimum Window Subsequence/README_EN.md
index 5607e7c495e0b..62a0a37bb8826 100644
--- a/solution/0700-0799/0727.Minimum Window Subsequence/README_EN.md
+++ b/solution/0700-0799/0727.Minimum Window Subsequence/README_EN.md
@@ -28,7 +28,7 @@ tags:
Input: s1 = "abcdebdde", s2 = "bde"
Output: "bcde"
-Explanation:
+Explanation:
"bcde" is the answer because it occurs before "bdde" which has the same length.
"deb" is not a smaller window because the elements of s2 in the window must occur in order.
diff --git a/solution/0700-0799/0763.Partition Labels/README.md b/solution/0700-0799/0763.Partition Labels/README.md
index 2d5e408dd4339..ade793587c0cf 100644
--- a/solution/0700-0799/0763.Partition Labels/README.md
+++ b/solution/0700-0799/0763.Partition Labels/README.md
@@ -19,7 +19,7 @@ tags:
-给你一个字符串 s 。我们要把这个字符串划分为尽可能多的片段,同一字母最多出现在一个片段中。
+给你一个字符串 s 。我们要把这个字符串划分为尽可能多的片段,同一字母最多出现在一个片段中。例如,字符串 "ababcc" 能够被分为 ["abab", "cc"],但类似 ["aba", "bcc"] 或 ["ab", "ab", "cc"] 的划分是非法的。
注意,划分结果需要满足:将所有划分结果按顺序连接,得到的字符串仍然是 s 。
diff --git a/solution/0800-0899/0801.Minimum Swaps To Make Sequences Increasing/README_EN.md b/solution/0800-0899/0801.Minimum Swaps To Make Sequences Increasing/README_EN.md
index 05cfa68361a31..8d9ecce1f87cb 100644
--- a/solution/0800-0899/0801.Minimum Swaps To Make Sequences Increasing/README_EN.md
+++ b/solution/0800-0899/0801.Minimum Swaps To Make Sequences Increasing/README_EN.md
@@ -33,7 +33,7 @@ tags:
Input: nums1 = [1,3,5,4], nums2 = [1,2,3,7]
Output: 1
-Explanation:
+Explanation:
Swap nums1[3] and nums2[3]. Then the sequences are:
nums1 = [1, 3, 5, 7] and nums2 = [1, 2, 3, 4]
which are both strictly increasing.
diff --git a/solution/0800-0899/0850.Rectangle Area II/README.md b/solution/0800-0899/0850.Rectangle Area II/README.md
index f921f836e1284..0f70a78b0554c 100644
--- a/solution/0800-0899/0850.Rectangle Area II/README.md
+++ b/solution/0800-0899/0850.Rectangle Area II/README.md
@@ -19,7 +19,7 @@ tags:
-给你一个轴对齐的二维数组 rectangles 。 对于 rectangle[i] = [x1, y1, x2, y2],其中(x1,y1)是矩形 i 左下角的坐标, (xi1, yi1) 是该矩形 左下角 的坐标, (xi2, yi2) 是该矩形 右上角 的坐标。
+给你一个轴对齐的二维数组 rectangles 。 对于 rectangle[i] = [x1, y1, x2, y2],其中 (xi1, yi1) 是该矩形 左下角 的坐标, (xi2, yi2) 是该矩形 右上角 的坐标。
计算平面中所有 rectangles 所覆盖的 总面积 。任何被两个或多个矩形覆盖的区域应只计算 一次 。
diff --git a/solution/1400-1499/1408.String Matching in an Array/README.md b/solution/1400-1499/1408.String Matching in an Array/README.md
index e241067294195..7ea0d439750a1 100644
--- a/solution/1400-1499/1408.String Matching in an Array/README.md
+++ b/solution/1400-1499/1408.String Matching in an Array/README.md
@@ -20,13 +20,11 @@ tags:
-给你一个字符串数组 words ,数组中的每个字符串都可以看作是一个单词。请你按 任意 顺序返回 words 中是其他单词的子字符串的所有单词。
-
-如果你可以删除 words[j] 最左侧和/或最右侧的若干字符得到 words[i] ,那么字符串 words[i] 就是 words[j] 的一个子字符串。
+给你一个字符串数组 words ,数组中的每个字符串都可以看作是一个单词。请你按 任意 顺序返回 words 中是其他单词的 子字符串 的所有单词。
-示例 1:
+示例 1:
输入:words = ["mass","as","hero","superhero"]
@@ -35,7 +33,7 @@ tags:
["hero","as"] 也是有效的答案。
-示例 2:
+示例 2:
输入:words = ["leetcode","et","code"]
@@ -43,7 +41,7 @@ tags:
解释:"et" 和 "code" 都是 "leetcode" 的子字符串。
-示例 3:
+示例 3:
输入:words = ["blue","green","bu"]
@@ -58,7 +56,7 @@ tags:
1 <= words.length <= 100
1 <= words[i].length <= 30
words[i] 仅包含小写英文字母。
- 题目数据 保证 每个 words[i] 都是独一无二的。
+ 题目数据 保证 words 的每个字符串都是独一无二的。
diff --git a/solution/1700-1799/1718.Construct the Lexicographically Largest Valid Sequence/README_EN.md b/solution/1700-1799/1718.Construct the Lexicographically Largest Valid Sequence/README_EN.md
index 1a16387860023..c59785bb39731 100644
--- a/solution/1700-1799/1718.Construct the Lexicographically Largest Valid Sequence/README_EN.md
+++ b/solution/1700-1799/1718.Construct the Lexicographically Largest Valid Sequence/README_EN.md
@@ -19,7 +19,7 @@ tags:
-Given an integer n, find a sequence that satisfies all of the following:
+Given an integer n, find a sequence with elements in the range [1, n] that satisfies all of the following:
- The integer
1 occurs once in the sequence.
diff --git a/solution/1700-1799/1730.Shortest Path to Get Food/README.md b/solution/1700-1799/1730.Shortest Path to Get Food/README.md
index 2da8adfc461c8..8d17306744f0e 100644
--- a/solution/1700-1799/1730.Shortest Path to Get Food/README.md
+++ b/solution/1700-1799/1730.Shortest Path to Get Food/README.md
@@ -55,6 +55,12 @@ tags:
输出: 6
解释: 这里有多个食物。拿到下边的食物仅需走 6 步。
+示例 4:
+
+
+输入:grid = [["X","X","X","X","X","X","X","X"],["X","*","O","X","O","#","O","X"],["X","O","O","X","O","O","X","X"],["X","O","O","O","O","#","O","X"],["O","O","O","O","O","O","O","O"]]
+输出:5
+
提示:
diff --git a/solution/1700-1799/1752.Check if Array Is Sorted and Rotated/README.md b/solution/1700-1799/1752.Check if Array Is Sorted and Rotated/README.md
index b1685b6f3975a..c45eecbc8686b 100644
--- a/solution/1700-1799/1752.Check if Array Is Sorted and Rotated/README.md
+++ b/solution/1700-1799/1752.Check if Array Is Sorted and Rotated/README.md
@@ -24,7 +24,7 @@ tags:
源数组中可能存在 重复项 。
-注意:我们称数组 A 在轮转 x 个位置后得到长度相同的数组 B ,当它们满足 A[i] == B[(i+x) % A.length] ,其中 % 为取余运算。
+注意:数组 A 在轮转 x 个位置后得到长度相同的数组 B ,使得对于每一个有效的下标 i,满足 B[i] == A[(i+x) % A.length]。
diff --git a/solution/1800-1899/1800.Maximum Ascending Subarray Sum/README.md b/solution/1800-1899/1800.Maximum Ascending Subarray Sum/README.md
index ac8eda0612e31..f5228430b1ca4 100644
--- a/solution/1800-1899/1800.Maximum Ascending Subarray Sum/README.md
+++ b/solution/1800-1899/1800.Maximum Ascending Subarray Sum/README.md
@@ -18,13 +18,11 @@ tags:
-给你一个正整数组成的数组 nums ,返回 nums 中一个 升序 子数组的最大可能元素和。
+给你一个正整数组成的数组 nums ,返回 nums 中一个 严格递增子数组 的最大可能元素和。
子数组是数组中的一个连续数字序列。
-已知子数组 [numsl, numsl+1, ..., numsr-1, numsr] ,若对所有 i(l <= i < r),numsi < numsi+1 都成立,则称这一子数组为 升序 子数组。注意,大小为 1 的子数组也视作 升序 子数组。
-
-
+
示例 1:
@@ -50,20 +48,13 @@ tags:
解释:[10,11,12] 是元素和最大的升序子数组,最大元素和为 33 。
-示例 4:
-
-
-输入:nums = [100,10,1]
-输出:100
-
-
-
+
提示:
- 1 <= nums.length <= 1001 <= nums[i] <= 1001 <= nums.length <= 1001 <= nums[i] <= 100
diff --git a/solution/1800-1899/1852.Distinct Numbers in Each Subarray/README.md b/solution/1800-1899/1852.Distinct Numbers in Each Subarray/README.md
index 69ca36aced8d7..9828a5b6752f3 100644
--- a/solution/1800-1899/1852.Distinct Numbers in Each Subarray/README.md
+++ b/solution/1800-1899/1852.Distinct Numbers in Each Subarray/README.md
@@ -18,9 +18,11 @@ tags:
-给你一个整数数组 nums与一个整数 k,请你构造一个长度 n-k+1 的数组 ans,这个数组第i个元素 ans[i] 是每个长度为k的子数组 nums[i:i+k-1] = [nums[i], nums[i+1], ..., nums[i+k-1]]中数字的种类数。
+给你一个长度为 n 的整数数组 nums 与一个整数 k。你的任务是找到 nums 所有 长度为 k 的子数组中 不同 元素的数量。
-返回这个数组 ans。
+返回一个数组 ans,其中 ans[i] 是对于每个索引 0 <= i < n - k,nums[i..(i + k - 1)] 中不同元素的数量。
+
+
@@ -30,11 +32,11 @@ tags:
输入: nums = [1,2,3,2,2,1,3], k = 3
输出: [3,2,2,2,3]
解释:每个子数组的数字种类计算方法如下:
-- nums[0:2] = [1,2,3] 所以 ans[0] = 3
-- nums[1:3] = [2,3,2] 所以 ans[1] = 2
-- nums[2:4] = [3,2,2] 所以 ans[2] = 2
-- nums[3:5] = [2,2,1] 所以 ans[3] = 2
-- nums[4:6] = [2,1,3] 所以 ans[4] = 3
+- nums[0..2] = [1,2,3] 所以 ans[0] = 3
+- nums[1..3] = [2,3,2] 所以 ans[1] = 2
+- nums[2..4] = [3,2,2] 所以 ans[2] = 2
+- nums[3..5] = [2,2,1] 所以 ans[3] = 2
+- nums[4..6] = [2,1,3] 所以 ans[4] = 3
示例 2:
@@ -43,10 +45,10 @@ tags:
输入: nums = [1,1,1,1,2,3,4], k = 4
输出: [1,2,3,4]
解释: 每个子数组的数字种类计算方法如下:
-- nums[0:3] = [1,1,1,1] 所以 ans[0] = 1
-- nums[1:4] = [1,1,1,2] 所以 ans[1] = 2
-- nums[2:5] = [1,1,2,3] 所以 ans[2] = 3
-- nums[3:6] = [1,2,3,4] 所以 ans[3] = 4
+- nums[0..3] = [1,1,1,1] 所以 ans[0] = 1
+- nums[1..4] = [1,1,1,2] 所以 ans[1] = 2
+- nums[2..5] = [1,1,2,3] 所以 ans[2] = 3
+- nums[3..6] = [1,2,3,4] 所以 ans[3] = 4
diff --git a/solution/1900-1999/1944.Number of Visible People in a Queue/README.md b/solution/1900-1999/1944.Number of Visible People in a Queue/README.md
index d4991ec8604b4..e00fbf6d637c1 100644
--- a/solution/1900-1999/1944.Number of Visible People in a Queue/README.md
+++ b/solution/1900-1999/1944.Number of Visible People in a Queue/README.md
@@ -72,15 +72,15 @@ tags:
我们观察发现,对于第 $i$ 个人来说,他能看到的人一定是按从左到右高度严格单调递增的。
-因此,我们可以倒序遍历数组 $heights$,用一个从栈顶到栈底单调递增的栈 $stk$ 记录已经遍历过的人的高度。
+因此,我们可以倒序遍历数组 $\textit{heights}$,用一个从栈顶到栈底单调递增的栈 $\textit{stk}$ 记录已经遍历过的人的高度。
-对于第 $i$ 个人,如果栈不为空并且栈顶元素小于 $heights[i]$,累加当前第 $i$ 个人能看到的人数,然后将栈顶元素出栈,直到栈为空或者栈顶元素大于等于 $heights[i]$。如果此时栈不为空,说明栈顶元素大于等于 $heights[i]$,那么第 $i$ 个人能看到的人数还要再加 $1$。
+对于第 $i$ 个人,如果栈不为空并且栈顶元素小于 $\textit{heights}[i]$,累加当前第 $i$ 个人能看到的人数,然后将栈顶元素出栈,直到栈为空或者栈顶元素大于等于 $\textit{heights}[i]$。如果此时栈不为空,说明栈顶元素大于等于 $\textit{heights}[i]$,那么第 $i$ 个人能看到的人数还要再加 $1$。
-接下来,我们将 $heights[i]$ 入栈,继续遍历下一个人。
+接下来,我们将 $\textit{heights}[i]$ 入栈,继续遍历下一个人。
-遍历结束后,返回答案数组 $ans$。
+遍历结束后,返回答案数组 $\textit{ans}$。
-时间复杂度 $O(n)$,空间复杂度 $O(n)$。其中 $n$ 是数组 $heights$ 的长度。
+时间复杂度 $O(n)$,空间复杂度 $O(n)$。其中 $n$ 是数组 $\textit{heights}$ 的长度。
相似题目:
diff --git a/solution/1900-1999/1944.Number of Visible People in a Queue/README_EN.md b/solution/1900-1999/1944.Number of Visible People in a Queue/README_EN.md
index 3858ce84f433d..8c6f2da6c9abd 100644
--- a/solution/1900-1999/1944.Number of Visible People in a Queue/README_EN.md
+++ b/solution/1900-1999/1944.Number of Visible People in a Queue/README_EN.md
@@ -66,7 +66,19 @@ Person 5 can see no one since nobody is to the right of them.
-### Solution 1
+### Solution 1: Monotonic Stack
+
+We observe that for the $i$-th person, the people he can see must be strictly increasing in height from left to right.
+
+Therefore, we can traverse the array $\textit{heights}$ in reverse order, using a stack $\textit{stk}$ that is monotonically increasing from top to bottom to record the heights of the people we have traversed.
+
+For the $i$-th person, if the stack is not empty and the top element of the stack is less than $\textit{heights}[i]$, we increment the count of people the $i$-th person can see, then pop the top element of the stack, until the stack is empty or the top element of the stack is greater than or equal to $\textit{heights}[i]$. If the stack is not empty at this point, it means the top element of the stack is greater than or equal to $\textit{heights}[i]$, so we increment the count of people the $i$-th person can see by 1.
+
+Next, we push $\textit{heights}[i]$ onto the stack and continue to the next person.
+
+After traversing, we return the answer array $\textit{ans}$.
+
+The time complexity is $O(n)$, and the space complexity is $O(n)$. Here, $n$ is the length of the array $\textit{heights}$.
diff --git a/solution/1900-1999/1945.Sum of Digits of String After Convert/README.md b/solution/1900-1999/1945.Sum of Digits of String After Convert/README.md
index 9948afc19cbf1..50728b36c3cb3 100644
--- a/solution/1900-1999/1945.Sum of Digits of String After Convert/README.md
+++ b/solution/1900-1999/1945.Sum of Digits of String After Convert/README.md
@@ -151,11 +151,15 @@ class Solution {
public:
int getLucky(string s, int k) {
string t;
- for (char c : s) t += to_string(c - 'a' + 1);
+ for (char c : s) {
+ t += to_string(c - 'a' + 1);
+ }
s = t;
while (k--) {
int t = 0;
- for (char c : s) t += c - '0';
+ for (char c : s) {
+ t += c - '0';
+ }
s = to_string(t);
}
return stoi(s);
diff --git a/solution/1900-1999/1945.Sum of Digits of String After Convert/README_EN.md b/solution/1900-1999/1945.Sum of Digits of String After Convert/README_EN.md
index e1c9aef5308f4..31ee92e191589 100644
--- a/solution/1900-1999/1945.Sum of Digits of String After Convert/README_EN.md
+++ b/solution/1900-1999/1945.Sum of Digits of String After Convert/README_EN.md
@@ -92,7 +92,11 @@ Thus the resulting integer is 6.
-### Solution 1
+### Solution 1: Simulation
+
+We can simulate the process described in the problem.
+
+The time complexity is $O(n)$, and the space complexity is $O(n)$. Here, $n$ is the length of the string $s$.
@@ -137,11 +141,15 @@ class Solution {
public:
int getLucky(string s, int k) {
string t;
- for (char c : s) t += to_string(c - 'a' + 1);
+ for (char c : s) {
+ t += to_string(c - 'a' + 1);
+ }
s = t;
while (k--) {
int t = 0;
- for (char c : s) t += c - '0';
+ for (char c : s) {
+ t += c - '0';
+ }
s = to_string(t);
}
return stoi(s);
diff --git a/solution/1900-1999/1945.Sum of Digits of String After Convert/Solution.cpp b/solution/1900-1999/1945.Sum of Digits of String After Convert/Solution.cpp
index 9458978233dcb..2d5a468817456 100644
--- a/solution/1900-1999/1945.Sum of Digits of String After Convert/Solution.cpp
+++ b/solution/1900-1999/1945.Sum of Digits of String After Convert/Solution.cpp
@@ -2,13 +2,17 @@ class Solution {
public:
int getLucky(string s, int k) {
string t;
- for (char c : s) t += to_string(c - 'a' + 1);
+ for (char c : s) {
+ t += to_string(c - 'a' + 1);
+ }
s = t;
while (k--) {
int t = 0;
- for (char c : s) t += c - '0';
+ for (char c : s) {
+ t += c - '0';
+ }
s = to_string(t);
}
return stoi(s);
}
-};
\ No newline at end of file
+};
diff --git a/solution/1900-1999/1976.Number of Ways to Arrive at Destination/README.md b/solution/1900-1999/1976.Number of Ways to Arrive at Destination/README.md
index ca77511e5a638..07280ec9ad7e8 100644
--- a/solution/1900-1999/1976.Number of Ways to Arrive at Destination/README.md
+++ b/solution/1900-1999/1976.Number of Ways to Arrive at Destination/README.md
@@ -30,8 +30,9 @@ tags:
示例 1:
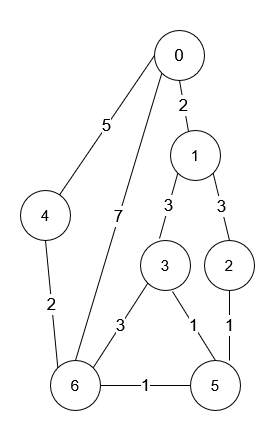
-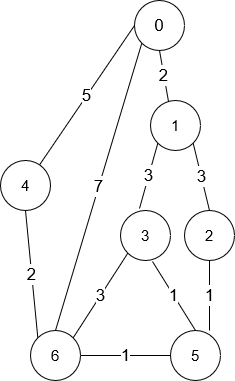 -
-输入:n = 7, roads = [[0,6,7],[0,1,2],[1,2,3],[1,3,3],[6,3,3],[3,5,1],[6,5,1],[2,5,1],[0,4,5],[4,6,2]]
+ +
+
+输入:n = 7, roads = [[0,6,7],[0,1,2],[1,2,3],[1,3,3],[6,3,3],[3,5,1],[6,5,1],[2,5,1],[0,4,5],[4,6,2]]
输出:4
解释:从路口 0 出发到路口 6 花费的最少时间是 7 分钟。
四条花费 7 分钟的路径分别为:
@@ -43,7 +44,8 @@ tags:
示例 2:
-输入:n = 2, roads = [[1,0,10]]
+
+输入:n = 2, roads = [[1,0,10]]
输出:1
解释:只有一条从路口 0 到路口 1 的路,花费 10 分钟。
diff --git a/solution/2100-2199/2115.Find All Possible Recipes from Given Supplies/README.md b/solution/2100-2199/2115.Find All Possible Recipes from Given Supplies/README.md
index 0994edfd43cef..9afb2f432dcc3 100644
--- a/solution/2100-2199/2115.Find All Possible Recipes from Given Supplies/README.md
+++ b/solution/2100-2199/2115.Find All Possible Recipes from Given Supplies/README.md
@@ -22,7 +22,7 @@ tags:
-你有 n 道不同菜的信息。给你一个字符串数组 recipes 和一个二维字符串数组 ingredients 。第 i 道菜的名字为 recipes[i] ,如果你有它 所有 的原材料 ingredients[i] ,那么你可以 做出 这道菜。一道菜的原材料可能是 另一道 菜,也就是说 ingredients[i] 可能包含 recipes 中另一个字符串。
+你有 n 道不同菜的信息。给你一个字符串数组 recipes 和一个二维字符串数组 ingredients 。第 i 道菜的名字为 recipes[i] ,如果你有它 所有 的原材料 ingredients[i] ,那么你可以 做出 这道菜。一份食谱也可以是 其它 食谱的原料,也就是说 ingredients[i] 可能包含 recipes 中另一个字符串。
同时给你一个字符串数组 supplies ,它包含你初始时拥有的所有原材料,每一种原材料你都有无限多。
@@ -34,7 +34,8 @@ tags:
示例 1:
-输入:recipes = ["bread"], ingredients = [["yeast","flour"]], supplies = ["yeast","flour","corn"]
+
+输入:recipes = ["bread"], ingredients = [["yeast","flour"]], supplies = ["yeast","flour","corn"]
输出:["bread"]
解释:
我们可以做出 "bread" ,因为我们有原材料 "yeast" 和 "flour" 。
@@ -42,7 +43,8 @@ tags:
示例 2:
-输入:recipes = ["bread","sandwich"], ingredients = [["yeast","flour"],["bread","meat"]], supplies = ["yeast","flour","meat"]
+
+输入:recipes = ["bread","sandwich"], ingredients = [["yeast","flour"],["bread","meat"]], supplies = ["yeast","flour","meat"]
输出:["bread","sandwich"]
解释:
我们可以做出 "bread" ,因为我们有原材料 "yeast" 和 "flour" 。
@@ -51,7 +53,8 @@ tags:
示例 3:
-输入:recipes = ["bread","sandwich","burger"], ingredients = [["yeast","flour"],["bread","meat"],["sandwich","meat","bread"]], supplies = ["yeast","flour","meat"]
+
+输入:recipes = ["bread","sandwich","burger"], ingredients = [["yeast","flour"],["bread","meat"],["sandwich","meat","bread"]], supplies = ["yeast","flour","meat"]
输出:["bread","sandwich","burger"]
解释:
我们可以做出 "bread" ,因为我们有原材料 "yeast" 和 "flour" 。
@@ -61,7 +64,8 @@ tags:
示例 4:
-输入:recipes = ["bread"], ingredients = [["yeast","flour"]], supplies = ["yeast"]
+
+输入:recipes = ["bread"], ingredients = [["yeast","flour"]], supplies = ["yeast"]
输出:[]
解释:
我们没法做出任何菜,因为我们只有原材料 "yeast" 。
diff --git a/solution/2100-2199/2116.Check if a Parentheses String Can Be Valid/README.md b/solution/2100-2199/2116.Check if a Parentheses String Can Be Valid/README.md
index 777169a24ad6b..af2d8402764d3 100644
--- a/solution/2100-2199/2116.Check if a Parentheses String Can Be Valid/README.md
+++ b/solution/2100-2199/2116.Check if a Parentheses String Can Be Valid/README.md
@@ -66,6 +66,15 @@ tags:
但无论将 s[0] 变为 '(' 或者 ')' 都无法使 s 变为有效字符串。
+示例 4:
+
+
+输入:s = "(((())(((())", locked = "111111010111"
+输出:false
+解释:locked 允许我们改变 s[6] 和 s[8]。
+我们将 s[6] 和 s[8] 改为 ')' 使 s 变为有效字符串。
+
+
提示:
diff --git a/solution/2100-2199/2161.Partition Array According to Given Pivot/README.md b/solution/2100-2199/2161.Partition Array According to Given Pivot/README.md
index efd76ad814049..01971fcc94e64 100644
--- a/solution/2100-2199/2161.Partition Array According to Given Pivot/README.md
+++ b/solution/2100-2199/2161.Partition Array According to Given Pivot/README.md
@@ -27,7 +27,7 @@ tags:
所有等于 pivot 的元素都出现在小于和大于 pivot 的元素 中间 。
小于 pivot 的元素之间和大于 pivot 的元素之间的 相对顺序 不发生改变。
- - 更正式的,考虑每一对
pi,pj ,pi 是初始时位置 i 元素的新位置,pj 是初始时位置 j 元素的新位置。对于小于 pivot 的元素,如果 i < j 且 nums[i] < pivot 和 nums[j] < pivot 都成立,那么 pi < pj 也成立。类似的,对于大于 pivot 的元素,如果 i < j 且 nums[i] > pivot 和 nums[j] > pivot 都成立,那么 pi < pj 。
+ - 更正式的,考虑每一对
pi,pj ,pi 是初始时位置 i 元素的新位置,pj 是初始时位置 j 元素的新位置。如果 i < j 且两个元素 都 小于(或大于)pivot,那么 pi < pj 。
@@ -38,7 +38,8 @@ tags:
示例 1:
-输入:nums = [9,12,5,10,14,3,10], pivot = 10
+
+输入:nums = [9,12,5,10,14,3,10], pivot = 10
输出:[9,5,3,10,10,12,14]
解释:
元素 9 ,5 和 3 小于 pivot ,所以它们在数组的最左边。
@@ -48,7 +49,8 @@ tags:
示例 2:
-输入:nums = [-3,4,3,2], pivot = 2
+
+输入:nums = [-3,4,3,2], pivot = 2
输出:[-3,2,4,3]
解释:
元素 -3 小于 pivot ,所以在数组的最左边。
diff --git a/solution/2200-2299/2209.Minimum White Tiles After Covering With Carpets/README_EN.md b/solution/2200-2299/2209.Minimum White Tiles After Covering With Carpets/README_EN.md
index a6d4c6fcd9c7f..29efc29d419e6 100644
--- a/solution/2200-2299/2209.Minimum White Tiles After Covering With Carpets/README_EN.md
+++ b/solution/2200-2299/2209.Minimum White Tiles After Covering With Carpets/README_EN.md
@@ -37,7 +37,7 @@ tags:
Input: floor = "10110101", numCarpets = 2, carpetLen = 2
Output: 2
-Explanation:
+Explanation:
The figure above shows one way of covering the tiles with the carpets such that only 2 white tiles are visible.
No other way of covering the tiles with the carpets can leave less than 2 white tiles visible.
@@ -47,7 +47,7 @@ No other way of covering the tiles with the carpets can leave less than 2 white
Input: floor = "11111", numCarpets = 2, carpetLen = 3
Output: 0
-Explanation:
+Explanation:
The figure above shows one way of covering the tiles with the carpets such that no white tiles are visible.
Note that the carpets are able to overlap one another.
diff --git a/solution/2200-2299/2211.Count Collisions on a Road/README_EN.md b/solution/2200-2299/2211.Count Collisions on a Road/README_EN.md
index 8f537773bedfe..e3057d15d2769 100644
--- a/solution/2200-2299/2211.Count Collisions on a Road/README_EN.md
+++ b/solution/2200-2299/2211.Count Collisions on a Road/README_EN.md
@@ -47,7 +47,7 @@ The collisions that will happen on the road are:
- Cars 2 and 3 will collide with each other. Since car 3 is stationary, the number of collisions becomes 2 + 1 = 3.
- Cars 3 and 4 will collide with each other. Since car 3 is stationary, the number of collisions becomes 3 + 1 = 4.
- Cars 4 and 5 will collide with each other. After car 4 collides with car 3, it will stay at the point of collision and get hit by car 5. The number of collisions becomes 4 + 1 = 5.
-Thus, the total number of collisions that will happen on the road is 5.
+Thus, the total number of collisions that will happen on the road is 5.
Example 2:
diff --git a/solution/2200-2299/2212.Maximum Points in an Archery Competition/README_EN.md b/solution/2200-2299/2212.Maximum Points in an Archery Competition/README_EN.md
index 7731a53d635d7..4e5c5e8a46a9a 100644
--- a/solution/2200-2299/2212.Maximum Points in an Archery Competition/README_EN.md
+++ b/solution/2200-2299/2212.Maximum Points in an Archery Competition/README_EN.md
@@ -52,7 +52,7 @@ tags:
Input: numArrows = 9, aliceArrows = [1,1,0,1,0,0,2,1,0,1,2,0]
Output: [0,0,0,0,1,1,0,0,1,2,3,1]
-Explanation: The table above shows how the competition is scored.
+Explanation: The table above shows how the competition is scored.
Bob earns a total point of 4 + 5 + 8 + 9 + 10 + 11 = 47.
It can be shown that Bob cannot obtain a score higher than 47 points.
diff --git a/solution/2300-2399/2330.Valid Palindrome IV/README.md b/solution/2300-2399/2330.Valid Palindrome IV/README.md
index 4529628c3a1fc..4bff9cf58b34b 100644
--- a/solution/2300-2399/2330.Valid Palindrome IV/README.md
+++ b/solution/2300-2399/2330.Valid Palindrome IV/README.md
@@ -41,7 +41,7 @@ tags:
解释: 能让 s 变成回文,且只用了两步操作的方案如下:
- 将 s[0] 变成 'b' ,得到 s = "ba" 。
- 将 s[1] 变成 'b' ,得到s = "bb" 。
-执行两步操作让 s 变成一个回文,所以返回 true 。
+执行两步操作让 s 变成一个回文,所以返回 true 。
示例 3:
diff --git a/solution/2300-2399/2342.Max Sum of a Pair With Equal Sum of Digits/README.md b/solution/2300-2399/2342.Max Sum of a Pair With Equal Sum of Digits/README.md
index f84ee9d0130f1..6745f3f12b999 100644
--- a/solution/2300-2399/2342.Max Sum of a Pair With Equal Sum of Digits/README.md
+++ b/solution/2300-2399/2342.Max Sum of a Pair With Equal Sum of Digits/README.md
@@ -23,7 +23,7 @@ tags:
给你一个下标从 0 开始的数组 nums ,数组中的元素都是 正 整数。请你选出两个下标 i 和 j(i != j),且 nums[i] 的数位和 与 nums[j] 的数位和相等。
-请你找出所有满足条件的下标 i 和 j ,找出并返回 nums[i] + nums[j] 可以得到的 最大值 。
+请你找出所有满足条件的下标 i 和 j ,找出并返回 nums[i] + nums[j] 可以得到的 最大值。如果不存在这样的下标对,返回 -1。
diff --git a/solution/2400-2499/2452.Words Within Two Edits of Dictionary/README.md b/solution/2400-2499/2452.Words Within Two Edits of Dictionary/README.md
index 4ab489e60e02e..28008554c5f3f 100644
--- a/solution/2400-2499/2452.Words Within Two Edits of Dictionary/README.md
+++ b/solution/2400-2499/2452.Words Within Two Edits of Dictionary/README.md
@@ -5,6 +5,7 @@ edit_url: https://github.com/doocs/leetcode/edit/main/solution/2400-2499/2452.Wo
rating: 1459
source: 第 90 场双周赛 Q2
tags:
+ - 字典树
- 数组
- 字符串
---
diff --git a/solution/2400-2499/2452.Words Within Two Edits of Dictionary/README_EN.md b/solution/2400-2499/2452.Words Within Two Edits of Dictionary/README_EN.md
index 129e720d9db6d..7513d06287f9f 100644
--- a/solution/2400-2499/2452.Words Within Two Edits of Dictionary/README_EN.md
+++ b/solution/2400-2499/2452.Words Within Two Edits of Dictionary/README_EN.md
@@ -5,6 +5,7 @@ edit_url: https://github.com/doocs/leetcode/edit/main/solution/2400-2499/2452.Wo
rating: 1459
source: Biweekly Contest 90 Q2
tags:
+ - Trie
- Array
- String
---
diff --git a/solution/2500-2599/2506.Count Pairs Of Similar Strings/README.md b/solution/2500-2599/2506.Count Pairs Of Similar Strings/README.md
index 85a3aadaf16bd..1c85c80ad364b 100644
--- a/solution/2500-2599/2506.Count Pairs Of Similar Strings/README.md
+++ b/solution/2500-2599/2506.Count Pairs Of Similar Strings/README.md
@@ -117,8 +117,7 @@ class Solution {
for (char c : s.toCharArray()) {
x |= 1 << (c - 'a');
}
- ans += cnt.getOrDefault(x, 0);
- cnt.merge(x, 1, Integer::sum);
+ ans += cnt.merge(x, 1, Integer::sum) - 1;
}
return ans;
}
diff --git a/solution/2500-2599/2506.Count Pairs Of Similar Strings/README_EN.md b/solution/2500-2599/2506.Count Pairs Of Similar Strings/README_EN.md
index 5b8769d10c83c..516fc215c97e0 100644
--- a/solution/2500-2599/2506.Count Pairs Of Similar Strings/README_EN.md
+++ b/solution/2500-2599/2506.Count Pairs Of Similar Strings/README_EN.md
@@ -115,8 +115,7 @@ class Solution {
for (char c : s.toCharArray()) {
x |= 1 << (c - 'a');
}
- ans += cnt.getOrDefault(x, 0);
- cnt.merge(x, 1, Integer::sum);
+ ans += cnt.merge(x, 1, Integer::sum) - 1;
}
return ans;
}
diff --git a/solution/2500-2599/2506.Count Pairs Of Similar Strings/Solution.java b/solution/2500-2599/2506.Count Pairs Of Similar Strings/Solution.java
index 08c792f033654..2a9fa5912a377 100644
--- a/solution/2500-2599/2506.Count Pairs Of Similar Strings/Solution.java
+++ b/solution/2500-2599/2506.Count Pairs Of Similar Strings/Solution.java
@@ -7,8 +7,7 @@ public int similarPairs(String[] words) {
for (char c : s.toCharArray()) {
x |= 1 << (c - 'a');
}
- ans += cnt.getOrDefault(x, 0);
- cnt.merge(x, 1, Integer::sum);
+ ans += cnt.merge(x, 1, Integer::sum) - 1;
}
return ans;
}
diff --git a/solution/2500-2599/2570.Merge Two 2D Arrays by Summing Values/README.md b/solution/2500-2599/2570.Merge Two 2D Arrays by Summing Values/README.md
index 611a865fc24ab..c8e01034a3274 100644
--- a/solution/2500-2599/2570.Merge Two 2D Arrays by Summing Values/README.md
+++ b/solution/2500-2599/2570.Merge Two 2D Arrays by Summing Values/README.md
@@ -33,7 +33,7 @@ tags:
- 只有在两个数组中至少出现过一次的 id 才能包含在结果数组内。
- - 每个 id 在结果数组中 只能出现一次 ,并且其对应的值等于两个数组中该 id 所对应的值求和。如果某个数组中不存在该 id ,则认为其对应的值等于
0 。
+ - 每个 id 在结果数组中 只能出现一次 ,并且其对应的值等于两个数组中该 id 所对应的值求和。如果某个数组中不存在该 id ,则假定其对应的值等于
0 。
返回结果数组。返回的数组需要按 id 以递增顺序排列。
@@ -42,7 +42,8 @@ tags:
示例 1:
-输入:nums1 = [[1,2],[2,3],[4,5]], nums2 = [[1,4],[3,2],[4,1]]
+
+输入:nums1 = [[1,2],[2,3],[4,5]], nums2 = [[1,4],[3,2],[4,1]]
输出:[[1,6],[2,3],[3,2],[4,6]]
解释:结果数组中包含以下元素:
- id = 1 ,对应的值等于 2 + 4 = 6 。
@@ -53,7 +54,8 @@ tags:
示例 2:
-输入:nums1 = [[2,4],[3,6],[5,5]], nums2 = [[1,3],[4,3]]
+
+输入:nums1 = [[2,4],[3,6],[5,5]], nums2 = [[1,3],[4,3]]
输出:[[1,3],[2,4],[3,6],[4,3],[5,5]]
解释:不存在共同 id ,在结果数组中只需要包含每个 id 和其对应的值。
diff --git a/solution/2500-2599/2595.Number of Even and Odd Bits/README.md b/solution/2500-2599/2595.Number of Even and Odd Bits/README.md
index eade6dc3ce73a..cf987722fa585 100644
--- a/solution/2500-2599/2595.Number of Even and Odd Bits/README.md
+++ b/solution/2500-2599/2595.Number of Even and Odd Bits/README.md
@@ -24,27 +24,39 @@ tags:
用 odd 表示在 n 的二进制形式(下标从 0 开始)中值为 1 的奇数下标的个数。
+请注意,在数字的二进制表示中,位下标的顺序 从右到左。
+
返回整数数组 answer ,其中 answer = [even, odd] 。
-示例 1:
+示例 1:
+
+
+
输入:n = 50
+
+
输出:[1,2]
+
+
解释:
+
+
50 的二进制表示是 110010。
+
+
在下标 1,4,5 对应的值为 1。
+
示例 2:
+
+
+
输入:n = 2
+
+
输出:[0,1]
-
输入:n = 17
-输出:[2,0]
-解释:17 的二进制形式是 10001 。
-下标 0 和 下标 4 对应的值为 1 。
-共有 2 个偶数下标,0 个奇数下标。
-
+
解释:
-
示例 2:
+
2 的二进制表示是 10。
-
输入:n = 2
-输出:[0,1]
-解释:2 的二进制形式是 10 。
-下标 1 对应的值为 1 。
-共有 0 个偶数下标,1 个奇数下标。
-
+
只有下标 1 对应的值为 1。
+
diff --git a/solution/2600-2699/2698.Find the Punishment Number of an Integer/README.md b/solution/2600-2699/2698.Find the Punishment Number of an Integer/README.md
index cbf9eec2d6087..60cdfa63d575a 100644
--- a/solution/2600-2699/2698.Find the Punishment Number of an Integer/README.md
+++ b/solution/2600-2699/2698.Find the Punishment Number of an Integer/README.md
@@ -35,7 +35,7 @@ tags:
输入:n = 10
输出:182
-解释:总共有 3 个整数 i 满足要求:
+解释:总共有 3 个范围在 [1, 10] 的整数 i 满足要求:
- 1 ,因为 1 * 1 = 1
- 9 ,因为 9 * 9 = 81 ,且 81 可以分割成 8 + 1 。
- 10 ,因为 10 * 10 = 100 ,且 100 可以分割成 10 + 0 。
@@ -47,7 +47,7 @@ tags:
输入:n = 37
输出:1478
-解释:总共有 4 个整数 i 满足要求:
+解释:总共有 4 个范围在 [1, 37] 的整数 i 满足要求:
- 1 ,因为 1 * 1 = 1
- 9 ,因为 9 * 9 = 81 ,且 81 可以分割成 8 + 1 。
- 10 ,因为 10 * 10 = 100 ,且 100 可以分割成 10 + 0 。
diff --git a/solution/3000-3099/3066.Minimum Operations to Exceed Threshold Value II/README.md b/solution/3000-3099/3066.Minimum Operations to Exceed Threshold Value II/README.md
index 32adad0ac5aad..0f7bd9660a65a 100644
--- a/solution/3000-3099/3066.Minimum Operations to Exceed Threshold Value II/README.md
+++ b/solution/3000-3099/3066.Minimum Operations to Exceed Threshold Value II/README.md
@@ -86,7 +86,7 @@ tags:
2 <= nums.length <= 2 * 105
1 <= nums[i] <= 109
1 <= k <= 109
- 输入保证答案一定存在,也就是说一定存在一个操作序列使数组中所有元素都大于等于 k 。
+ 输入保证答案一定存在,也就是说,在进行某些次数的操作后,数组中所有元素都大于等于 k 。
diff --git a/solution/3100-3199/3160.Find the Number of Distinct Colors Among the Balls/README.md b/solution/3100-3199/3160.Find the Number of Distinct Colors Among the Balls/README.md
index 7c2a9221b2611..8d36b7bc5deb3 100644
--- a/solution/3100-3199/3160.Find the Number of Distinct Colors Among the Balls/README.md
+++ b/solution/3100-3199/3160.Find the Number of Distinct Colors Among the Balls/README.md
@@ -22,9 +22,9 @@ tags:
给你一个整数 limit 和一个大小为 n x 2 的二维数组 queries 。
-总共有 limit + 1 个球,每个球的编号为 [0, limit] 中一个 互不相同 的数字。一开始,所有球都没有颜色。queries 中每次操作的格式为 [x, y] ,你需要将球 x 染上颜色 y 。每次操作之后,你需要求出所有球中 不同 颜色的数目。
+总共有 limit + 1 个球,每个球的编号为 [0, limit] 中一个 互不相同 的数字。一开始,所有球都没有颜色。queries 中每次操作的格式为 [x, y] ,你需要将球 x 染上颜色 y 。每次操作之后,你需要求出所有球颜色的数目。
-请你返回一个长度为 n 的数组 result ,其中 result[i] 是第 i 次操作以后不同颜色的数目。
+请你返回一个长度为 n 的数组 result ,其中 result[i] 是第 i 次操作以后颜色的数目。
注意 ,没有染色的球不算作一种颜色。
diff --git a/solution/3200-3299/3223.Minimum Length of String After Operations/README.md b/solution/3200-3299/3223.Minimum Length of String After Operations/README.md
index 2c8b73da51db6..17e120cfd861b 100644
--- a/solution/3200-3299/3223.Minimum Length of String After Operations/README.md
+++ b/solution/3200-3299/3223.Minimum Length of String After Operations/README.md
@@ -26,8 +26,8 @@ tags:
- 选择一个下标
i ,满足 s[i] 左边和右边都 至少 有一个字符与它相同。
- - 删除
s[i] 左边 离它 最近 且相同的字符。
- - 删除
s[i] 右边 离它 最近 且相同的字符。
+ - 删除
i 左边 离它 最近 的 s[i] 字符。
+ - 删除
i 右边 离它 最近 的 s[i] 字符。
请你返回执行完所有操作后, s 的 最短 长度。
diff --git a/solution/3400-3499/3447.Assign Elements to Groups with Constraints/README.md b/solution/3400-3499/3447.Assign Elements to Groups with Constraints/README.md
index 5705c958778f8..ef35bbc68477a 100644
--- a/solution/3400-3499/3447.Assign Elements to Groups with Constraints/README.md
+++ b/solution/3400-3499/3447.Assign Elements to Groups with Constraints/README.md
@@ -22,8 +22,8 @@ tags:
请你根据以下规则为每个组分配 一个 元素:
- - 如果
groups[i] 能被 elements[j] 整除,则元素 j 可以分配给组 i。
- - 如果有多个元素满足条件,则分配下标最小的元素
j 。
+ - 如果
groups[i] 能被 elements[j] 整除,则下标为 j 的元素可以分配给组 i。
+ - 如果有多个元素满足条件,则分配 最小的下标
j 的元素。
- 如果没有元素满足条件,则分配 -1 。
diff --git a/solution/3400-3499/3447.Assign Elements to Groups with Constraints/README_EN.md b/solution/3400-3499/3447.Assign Elements to Groups with Constraints/README_EN.md
index 662039632bd39..fc83f00a2ca84 100644
--- a/solution/3400-3499/3447.Assign Elements to Groups with Constraints/README_EN.md
+++ b/solution/3400-3499/3447.Assign Elements to Groups with Constraints/README_EN.md
@@ -22,7 +22,7 @@ tags:
Your task is to assign one element to each group based on the following rules:
- - An element
j can be assigned to a group i if groups[i] is divisible by elements[j].
+ - An element at index
j can be assigned to a group i if groups[i] is divisible by elements[j].
- If there are multiple elements that can be assigned, assign the element with the smallest index
j.
- If no element satisfies the condition for a group, assign -1 to that group.
diff --git a/solution/3400-3499/3450.Maximum Students on a Single Bench/README.md b/solution/3400-3499/3450.Maximum Students on a Single Bench/README.md
index d3d9039f84814..72e931de0694e 100644
--- a/solution/3400-3499/3450.Maximum Students on a Single Bench/README.md
+++ b/solution/3400-3499/3450.Maximum Students on a Single Bench/README.md
@@ -17,6 +17,85 @@ tags:
+给定一个包含学生数据的 2 维数组 students,其中 students[i] = [student_id, bench_id] 表示学生 student_id 正坐在长椅 bench_id 上。
+
+返回单个长凳上坐着的不同学生的 最大 数量。如果没有学生,返回 0。
+
+注意:一个学生在输入中可以出现在同一张长椅上多次,但每个长椅上只能计算一次。
+
+
+
+示例 1:
+
+
+
输入:students = [[1,2],[2,2],[3,3],[1,3],[2,3]]
+
+
输出:3
+
+
解释:
+
+
+ - 长椅 2 上有 2 个不同学生:
[1, 2]。
+ - 长椅 3 上有 3 个不同学生:
[1, 2, 3]。
+ - 一张长椅上不同学生的最大数量是 3。
+
+
示例 2:
+
+
+
输入:students = [[1,1],[2,1],[3,1],[4,2],[5,2]]
+
+
输出:3
+
+
示例:
+
+
+ - 长椅 1 上有 3 个不同学生:
[1, 2, 3]。
+ - 长椅 2 上有 2 个不同学生:
[4, 5]。
+ - 一张长椅上不同学生的最大数量是 3。
+
+
示例 3:
+
+
+
输入:students = [[1,1],[1,1]]
+
+
输出:1
+
+
解释:
+
+
+
示例 4:
+
+
+
输入:students = []
+
+
输出:0
+
+
解释:
+
+
+
+
+提示:
+
+
+ 0 <= students.length <= 100students[i] = [student_id, bench_id]1 <= student_id <= 1001 <= bench_id <= 100
+
## 解法
diff --git a/solution/3400-3499/3450.Maximum Students on a Single Bench/README_EN.md b/solution/3400-3499/3450.Maximum Students on a Single Bench/README_EN.md
index e334f7c30ee39..337cac2fb7d02 100644
--- a/solution/3400-3499/3450.Maximum Students on a Single Bench/README_EN.md
+++ b/solution/3400-3499/3450.Maximum Students on a Single Bench/README_EN.md
@@ -17,7 +17,82 @@ tags:
-None
+You are given a 2D integer array of student data students, where students[i] = [student_id, bench_id] represents that student student_id is sitting on the bench bench_id.
+
+Return the maximum number of unique students sitting on any single bench. If no students are present, return 0.
+
+Note: A student can appear multiple times on the same bench in the input, but they should be counted only once per bench.
+
+
+Example 1:
+
+
+
Input: students = [[1,2],[2,2],[3,3],[1,3],[2,3]]
+
+
Output: 3
+
+
Explanation:
+
+
+ - Bench 2 has two unique students:
[1, 2].
+ - Bench 3 has three unique students:
[1, 2, 3].
+ - The maximum number of unique students on a single bench is 3.
+
+
Example 2:
+
+
+
Input: students = [[1,1],[2,1],[3,1],[4,2],[5,2]]
+
+
Output: 3
+
+
Explanation:
+
+
+ - Bench 1 has three unique students:
[1, 2, 3].
+ - Bench 2 has two unique students:
[4, 5].
+ - The maximum number of unique students on a single bench is 3.
+
+
Example 3:
+
+
+
Input: students = [[1,1],[1,1]]
+
+
Output: 1
+
+
Explanation:
+
+
+ - The maximum number of unique students on a single bench is 1.
+
+
Example 4:
+
+
+
Input: students = []
+
+
Output: 0
+
+
Explanation:
+
+
+ - Since no students are present, the output is 0.
+
+
+Constraints:
+
+
+ 0 <= students.length <= 100students[i] = [student_id, bench_id]1 <= student_id <= 1001 <= bench_id <= 100
diff --git a/solution/3400-3499/3453.Separate Squares I/README.md b/solution/3400-3499/3453.Separate Squares I/README.md
index fbdd39fad4695..215b7c9a5353c 100644
--- a/solution/3400-3499/3453.Separate Squares I/README.md
+++ b/solution/3400-3499/3453.Separate Squares I/README.md
@@ -72,6 +72,7 @@ tags:
squares[i].length == 3
0 <= xi, yi <= 109
1 <= li <= 109
+ 所有正方形的总面积不超过 1012。
diff --git a/solution/3400-3499/3454.Separate Squares II/README.md b/solution/3400-3499/3454.Separate Squares II/README.md
index 886a31db50fd5..3ee46b6633041 100644
--- a/solution/3400-3499/3454.Separate Squares II/README.md
+++ b/solution/3400-3499/3454.Separate Squares II/README.md
@@ -67,6 +67,7 @@ tags:
squares[i].length == 3
0 <= xi, yi <= 109
1 <= li <= 109
+ 所有正方形的总面积不超过 1015。
diff --git a/solution/3400-3499/3460.Longest Common Prefix After at Most One Removal/README.md b/solution/3400-3499/3460.Longest Common Prefix After at Most One Removal/README.md
index e743cfdbf1642..13cb2499f9251 100644
--- a/solution/3400-3499/3460.Longest Common Prefix After at Most One Removal/README.md
+++ b/solution/3400-3499/3460.Longest Common Prefix After at Most One Removal/README.md
@@ -14,6 +14,72 @@ edit_url: https://github.com/doocs/leetcode/edit/main/solution/3400-3499/3460.Lo
+给定两个字符串 s 和 t。
+
+返回从 s 最多 删除一个字母后,s 和 t 的 最长公共 前缀 的 长度。
+
+注意:可以保留 s 而不做任何删除。
+
+
+
+示例 1:
+
+
+
输入:s = "madxa", t = "madam"
+
+
输出:4
+
+
解释:
+
+
从 s 删除 s[3] 得到 "mada",与 t 的最长公共前缀长度为 4。
+
示例 2:
+
+
+
输入:s = "leetcode", t = "eetcode"
+
+
输出:7
+
+
解释:
+
+
从 s 删除 s[0] 得到 "eetcode",与 t 匹配。
+
示例 3:
+
+
+
输入:s = "one", t = "one"
+
+
输出:3
+
+
解释:
+
+
不需要删除。
+
示例 4:
+
+
+
输入:s = "a", t = "b"
+
+
输出:0
+
+
解释:
+
+
s 和 t 不可能有公共前缀。
+
+
+提示:
+
+
+ 1 <= s.length <= 1051 <= t.length <= 105s 和 t 只包含小写英文字母。
+
## 解法
diff --git a/solution/3400-3499/3460.Longest Common Prefix After at Most One Removal/README_EN.md b/solution/3400-3499/3460.Longest Common Prefix After at Most One Removal/README_EN.md
index 1a04a2926b151..d69d8b398493e 100644
--- a/solution/3400-3499/3460.Longest Common Prefix After at Most One Removal/README_EN.md
+++ b/solution/3400-3499/3460.Longest Common Prefix After at Most One Removal/README_EN.md
@@ -14,7 +14,69 @@ edit_url: https://github.com/doocs/leetcode/edit/main/solution/3400-3499/3460.Lo
-None
+You are given two strings s and t.
+
+Return the length of the longest common prefix between s and t after removing at most one character from s.
+
+Note: s can be left without any removal.
+
+
+Example 1:
+
+
+
Input: s = "madxa", t = "madam"
+
+
Output: 4
+
+
Explanation:
+
+
Removing s[3] from s results in "mada", which has a longest common prefix of length 4 with t.
+
Example 2:
+
+
+
Input: s = "leetcode", t = "eetcode"
+
+
Output: 7
+
+
Explanation:
+
+
Removing s[0] from s results in "eetcode", which matches t.
+
Example 3:
+
+
+
Input: s = "one", t = "one"
+
+
Output: 3
+
+
Explanation:
+
+
No removal is needed.
+
Example 4:
+
+
+
Input: s = "a", t = "b"
+
+
Output: 0
+
+
Explanation:
+
+
s and t cannot have a common prefix.
+
+Constraints:
+
+
+ 1 <= s.length <= 1051 <= t.length <= 105s and t contain only lowercase English letters.
diff --git a/solution/README.md b/solution/README.md
index ff80698f8aa47..a0e58db5279e9 100644
--- a/solution/README.md
+++ b/solution/README.md
@@ -2462,7 +2462,7 @@
| 2449 | [使数组相似的最少操作次数](/solution/2400-2499/2449.Minimum%20Number%20of%20Operations%20to%20Make%20Arrays%20Similar/README.md) | `贪心`,`数组`,`排序` | 困难 | 第 316 场周赛 |
| 2450 | [应用操作后不同二进制字符串的数量](/solution/2400-2499/2450.Number%20of%20Distinct%20Binary%20Strings%20After%20Applying%20Operations/README.md) | `数学`,`字符串` | 中等 | 🔒 |
| 2451 | [差值数组不同的字符串](/solution/2400-2499/2451.Odd%20String%20Difference/README.md) | `数组`,`哈希表`,`字符串` | 简单 | 第 90 场双周赛 |
-| 2452 | [距离字典两次编辑以内的单词](/solution/2400-2499/2452.Words%20Within%20Two%20Edits%20of%20Dictionary/README.md) | `数组`,`字符串` | 中等 | 第 90 场双周赛 |
+| 2452 | [距离字典两次编辑以内的单词](/solution/2400-2499/2452.Words%20Within%20Two%20Edits%20of%20Dictionary/README.md) | `字典树`,`数组`,`字符串` | 中等 | 第 90 场双周赛 |
| 2453 | [摧毁一系列目标](/solution/2400-2499/2453.Destroy%20Sequential%20Targets/README.md) | `数组`,`哈希表`,`计数` | 中等 | 第 90 场双周赛 |
| 2454 | [下一个更大元素 IV](/solution/2400-2499/2454.Next%20Greater%20Element%20IV/README.md) | `栈`,`数组`,`二分查找`,`排序`,`单调栈`,`堆(优先队列)` | 困难 | 第 90 场双周赛 |
| 2455 | [可被三整除的偶数的平均值](/solution/2400-2499/2455.Average%20Value%20of%20Even%20Numbers%20That%20Are%20Divisible%20by%20Three/README.md) | `数组`,`数学` | 简单 | 第 317 场周赛 |
diff --git a/solution/README_EN.md b/solution/README_EN.md
index 21a1a0efa95c0..3cf852229c57b 100644
--- a/solution/README_EN.md
+++ b/solution/README_EN.md
@@ -2460,7 +2460,7 @@ Press Control + F(or Command + F on
| 2449 | [Minimum Number of Operations to Make Arrays Similar](/solution/2400-2499/2449.Minimum%20Number%20of%20Operations%20to%20Make%20Arrays%20Similar/README_EN.md) | `Greedy`,`Array`,`Sorting` | Hard | Weekly Contest 316 |
| 2450 | [Number of Distinct Binary Strings After Applying Operations](/solution/2400-2499/2450.Number%20of%20Distinct%20Binary%20Strings%20After%20Applying%20Operations/README_EN.md) | `Math`,`String` | Medium | 🔒 |
| 2451 | [Odd String Difference](/solution/2400-2499/2451.Odd%20String%20Difference/README_EN.md) | `Array`,`Hash Table`,`String` | Easy | Biweekly Contest 90 |
-| 2452 | [Words Within Two Edits of Dictionary](/solution/2400-2499/2452.Words%20Within%20Two%20Edits%20of%20Dictionary/README_EN.md) | `Array`,`String` | Medium | Biweekly Contest 90 |
+| 2452 | [Words Within Two Edits of Dictionary](/solution/2400-2499/2452.Words%20Within%20Two%20Edits%20of%20Dictionary/README_EN.md) | `Trie`,`Array`,`String` | Medium | Biweekly Contest 90 |
| 2453 | [Destroy Sequential Targets](/solution/2400-2499/2453.Destroy%20Sequential%20Targets/README_EN.md) | `Array`,`Hash Table`,`Counting` | Medium | Biweekly Contest 90 |
| 2454 | [Next Greater Element IV](/solution/2400-2499/2454.Next%20Greater%20Element%20IV/README_EN.md) | `Stack`,`Array`,`Binary Search`,`Sorting`,`Monotonic Stack`,`Heap (Priority Queue)` | Hard | Biweekly Contest 90 |
| 2455 | [Average Value of Even Numbers That Are Divisible by Three](/solution/2400-2499/2455.Average%20Value%20of%20Even%20Numbers%20That%20Are%20Divisible%20by%20Three/README_EN.md) | `Array`,`Math` | Easy | Weekly Contest 317 |