Replies: 8 comments 3 replies
-
|
I'm fairly new to the VSCode internals - but if it works how I think it does, shouldn't we have transport-layer encryption provided by the websocket if we have a cert provided? |
Beta Was this translation helpful? Give feedback.
-
You mean the transport layer encryption at the webSocket, I know, but I want to encrypt data on the application layer😅 |
Beta Was this translation helpful? Give feedback.
-
|
There is an abstraction on top of the messages sent across the socket. There is a header with some information then a body after that (you can see the documentation for this in There are further abstractions on top of that in some cases, like with channels which add their own header and body as well. There may be others but those are all the ones I know of. |
Beta Was this translation helpful? Give feedback.
-
|
In fact I don't think there's any guarantee the body is a string so any kind of general conversion is probably going to have issues. |
Beta Was this translation helpful? Give feedback.
-
Now I have completed the first simply encryption, split the client data into header, body, footer, then encrypt the body data(code fragment), and then divide the body into header, body, and footer when the server receives it in the _acceptChunk function, and then fire the body( However, this kind of websocket encryption is successful under a certain amount of code (about 1200 lines of code), but too much code will trigger the reconnection mechanism due to acceptChunck's block transmission. Is there any way to solve this problem or other ideas of encryption? Help😅 |

Beta Was this translation helpful? Give feedback.
-
|
Couldn't you encrypt and decrypt the entire message without having to do
any splitting?
|
Beta Was this translation helpful? Give feedback.
-
If you do not split, because of some special identifiers of header and footer, the encrypted data will not be successfully decrypted on the server. Now I am using CryptoJS AES encryption and decryption. Since the string can be encrypted and decrypted directly after splitting, there is no need to consider converting to base64. The problem now lies in the acceptChunck's block transmission when the amount of code is large(about 1200+ lines of code). I think this splitting may have limitations. Are there any other good encryption methods to fix?🥺 // encrypt and decrypt after splitting
import * as CryptoJS from 'crypto-js'
// 1. the encrypt func in the client
function encrypt(word: string): string {
let encJson = CryptoJS.AES.encrypt(JSON.stringify(word), key).toString()
let encData = CryptoJS.enc.Base64.stringify(CryptoJS.enc.Utf8.parse(encJson))
return encData
}
//2. the decrypt func in the node server
function decrypt(word: string): string {
let decData = CryptoJS.enc.Base64.parse(word).toString(CryptoJS.enc.Utf8)
let bytes = CryptoJS.AES.decrypt(decData, key).toString(CryptoJS.enc.Utf8)
return JSON.parse(bytes)
} |
Beta Was this translation helpful? Give feedback.
-
|
I think splitting will be dangerous because there's no guarantee a chunk has a header or a body. It could be half a header or have multiple headers and bodies or not have any headers and bodies at all or have a body that itself also has a header and a body, etc. You might have success if you encrypt and decrypt at the points where the socket sends and receives messages. Maybe here: const listener = (buff: Buffer) => _listener(VSBuffer.wrap(decrypt(buff))); And here: this.socket.write(encrypt(<Buffer>buffer.buffer));Where |
Beta Was this translation helpful? Give feedback.
-
|
📄I reorganized my question. u know, now the websocket of code-server is not encrypted at the application layer, you can capture it with a packet capture tool. Now I need to encrypt the application layer for security. As shown in the figure below, you can clearly see the transmitted code in network-ws tab, which is easy to be crawled, and websocket is triggered when the code changes. 💡My idea is as follows, the whole process is divided into four parts:
🤔So I have 2 questions for now Q1: Can this websocket encryption requirement be successfully realized? Q2: In client and server, is there a way to directly encrypt Buffer? (It seems that some garbled characters will appear when converted to string, resulting in failure to convert) |
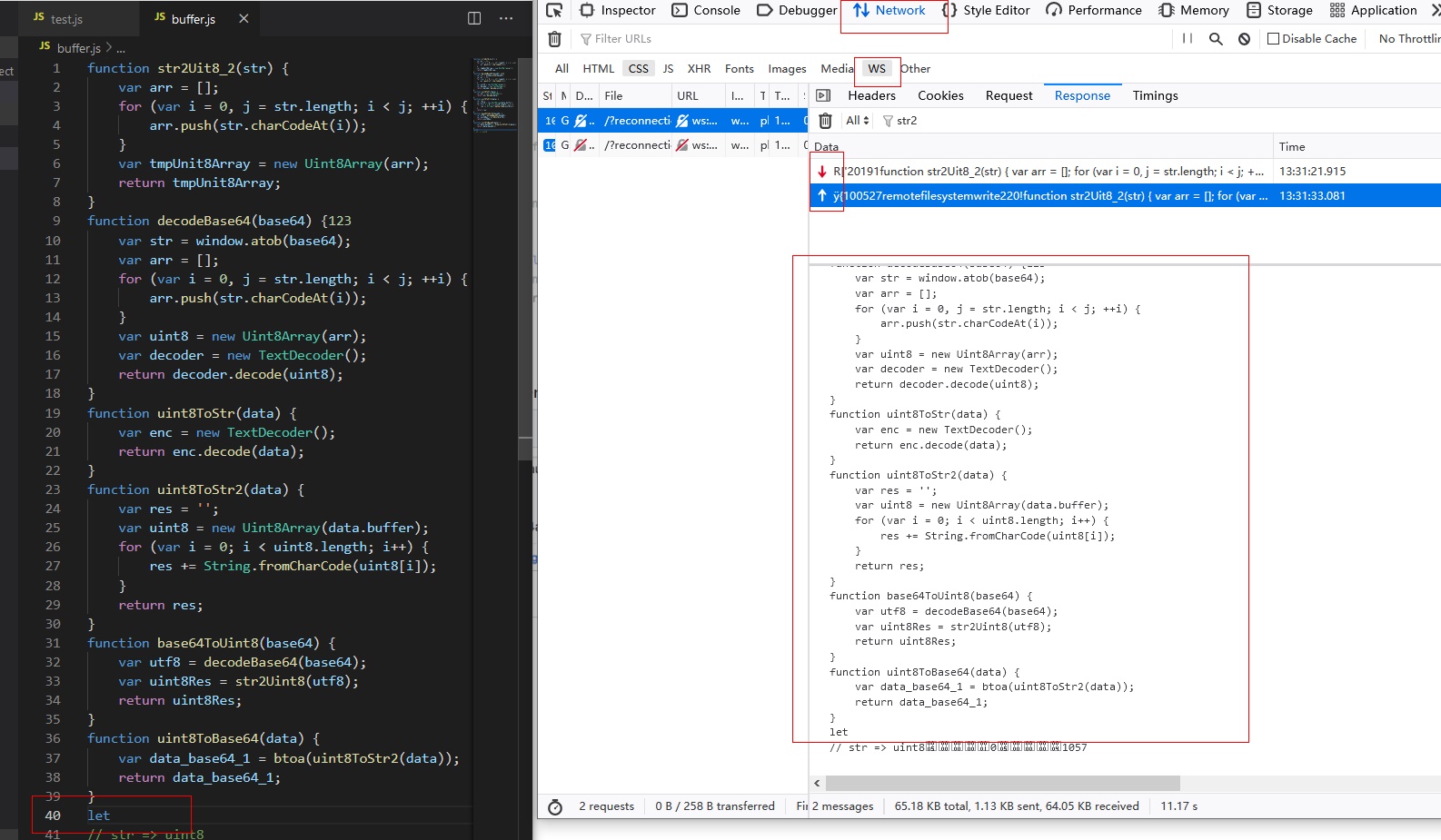
Beta Was this translation helpful? Give feedback.
-
|
Have you resolved this issue, and if so, what is your solution? |
Beta Was this translation helpful? Give feedback.
-
|
@OFEII does https solve this? |
Beta Was this translation helpful? Give feedback.
-
Q: About the encryption and the decryption of the socekt communication between the browser client and the node server
For the privacy of users, it is now necessary to encrypt and decrypt the data between the browser client and the node server socekt communication.
By studying the source code of vscode, I found some code fragments related to data about the socekt communication, like
browser/browserSocketFactory.tsandnode/ipc.net.ts.I tried countless times, but all failed. I think the key of this question lies in the conversion of data types(like uint8Array, VSbuffer...)
What puzzles me is that when I convert the received buffer from the browser client (VsBuffer => string => VsBuffer) in the
node/ipc.net.ts. The result of the buffer before and after the conversion is unexpected, the length of the VsBuffer is the same, but a small part of the converted Vsbuffer has changed. I guess it may be caused by garbled characters after being converted to string, so what is the coding scheme of the garbled characters, unlike ASCII, UTF-8, Unicode..., as shown below:But if I use the built-in-method of the Vsbuffer to convert (VsBuffer => string => VsBuffer), the length and buffer content of the buffer before and after is inconsistent.
Now my thoughts are blocked, maybe. How can I complete this function by modifying the source code of vscode?
Beta Was this translation helpful? Give feedback.
All reactions